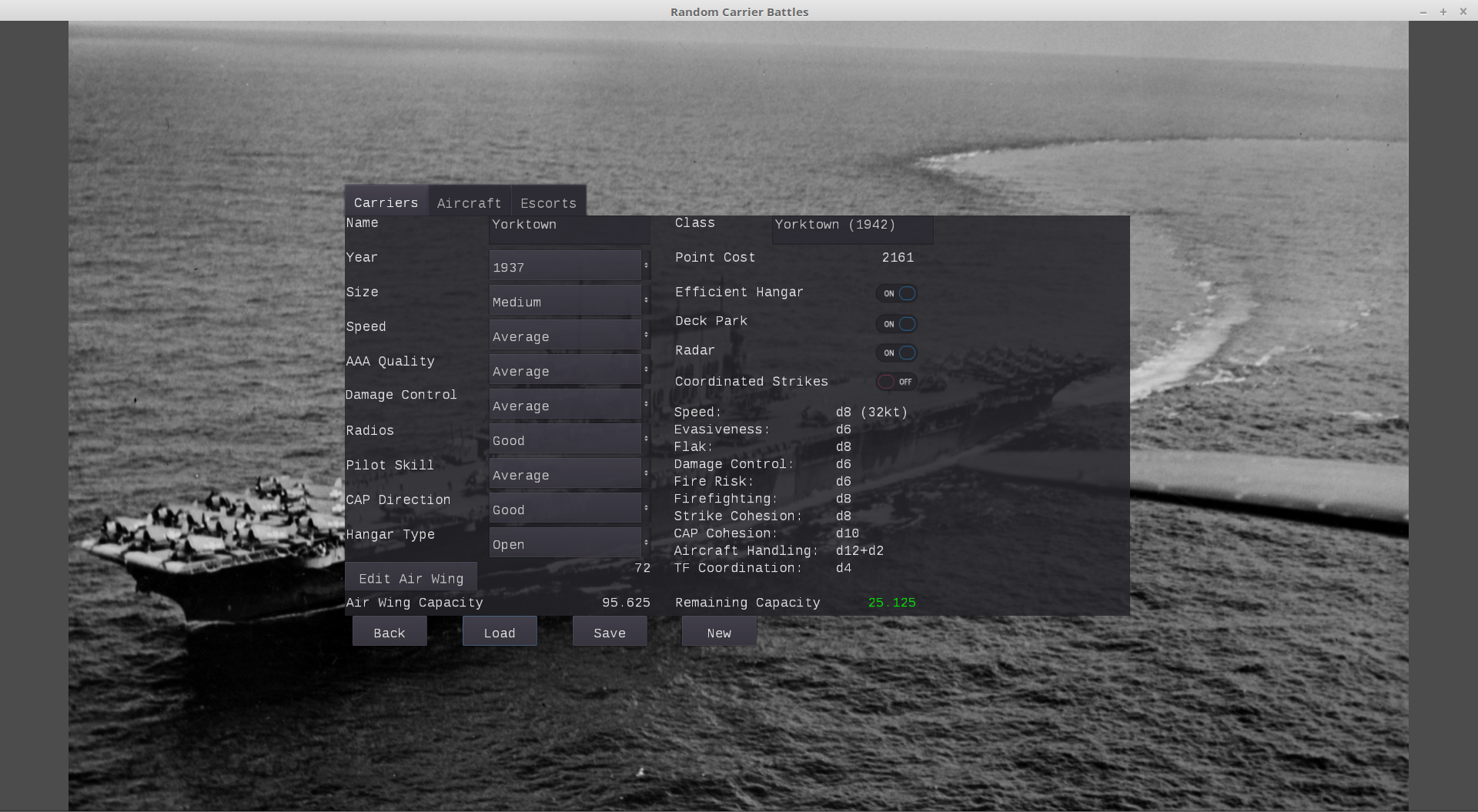
Coming soon, or at least at some point down the line, from the Softworks division of Many Words Press, Random Carrier Battles:
Random Carrier Battles is a computer wargame simulating aircraft carrier warfare at the operational level between the mid-1930s and the end of the Second World War. It features a user-friendly design system for carriers, escorts, and aircraft, along with a large library of predefined types for your convenience. Planned features include a scenario editor and a random scenario generator, along with some premade scenarios covering major battles in the Second World War.
If you listened to Episode 12 of The Crossbox Podcast, you’ll remember my goal for the design system: create something just complex enough to adequately capture the different schools of carrier design in the era in question.
In scenarios, the player fills the role of the admiral in command, controlling the composition and disposition of the task force or task forces under his control, as well as the tempo and target of air operations. Hands-on admirals will be able to control aircraft handling down to the individual plane aboard their carriers; big-picture admirals will be able to delegate those to the computer.
Both kinds of admiral will have plenty to sink their teeth into strategically: Random Carrier Battles will accurately model the uncertainties inherent in carrier warfare, including incorrect spotting reports and communications failures, incomplete information about enemies, and lack of direct control over aircraft.
Obviously, this project is still in its infancy. I’ll be blogging about the development process here (at least until it’s far enough along for its own website), and sharing more screenshots and videos as things progress. Stay tuned for more information in the months to come!
That’s right, ladies and gentlemen, one month until entries close. I’ve posted final deadlines and submission guidelines at the official tournament page; have a look and get ready.
During the tournament, expect coverage here, possibly to include some liveblogged or streamed games. See you in a month!
This is the third article in a series of posts on OpenTafl. You can read the first and second parts at the preceding links.
Welcome back to the third and final entry in Opentaflvecken, a one-week period in which I provide some minor respite to poor parvusimperator. We’ve hit the major AI improvements; now it’s time to cover a grab bag of miscellaneous topics left over. Onward!
Playing out repetitions In OpenTafl’s versions of tafl rule sets, threefold repetitions are invariably handled: by default, it yields a draw; some variants define a threefold repetition as a win for the player moving into the third repetition of a board state1. Prior to the AI improvements release, the AI simply ignored repetitions, an obvious weakness: if you found a position where you could force OpenTafl to make repeated moves to defend, you could play the forcing move over and over, and OpenTafl would obligingly find a different way to answer it until it ran out and let you win. No longer! Now, OpenTafl is smart enough to play repetitions out to the end, using them to win if possible, or forcing a draw if necessary.
It turns out, as with everything in AI, this is not as simple as it sounds. The problem is the transposition table. It has no information on how many times a position has been repeated, and repetition rules introduce path dependency: the history of a state matters in its evaluation. Fortunately, this is a very simple path dependency to solve. OpenTafl now has a smallish hash table containing Zobrist hashes and repetition counts. Whenever a position appears, either in the AI search or in the regular play of the game, the repetition count is incremented. Whenever the AI finishes searching a position, it is removed from the table. In this way, at any given state, the AI always knows how many times a position has occurred. If the position has occurred more than once in the past, the AI skips the transposition table lookup and searches the position instead. This seems like it might cause a search slowdown—repetitions can no longer be probed—but in practice, it’s turned out to have almost no effect.
Move ordering improvements I discussed move ordering a little bit in the second article, but I want to go into a little more depth. Move ordering is the beating heart of any alpha-beta search engine. The better the move ordering, the better the pruning works; the better the pruning works, the deeper the AI can search; the deeper the AI can search, the better it plays. Early on in OpenTafl’s development, I threw together a very simple move ordering function: it searched captures first and everything else later. Later on, after the transposition table went in, I added a bit to try transposition table hits in between captures and the remaining moves. The move ordering used Java’s sort method, which, though efficient, is more ordering than is necessary.
Late in the AI improvements branch, when I added the killer move table and the history table, I decided to fix that. Move ordering now does as little work as possible: it makes one pass through the list of moves, putting them into buckets according to their move type. It sorts the transposition table hits and history table hits, then searches the killer moves, the history table hits, the top half of the transposition table hits, the captures, the bottom half of the transposition table hits, and finally, any moves which remain. Though there are two sorts here instead one, since they’re much smaller on average, they’re faster overall.
Puzzles Okay, this one isn’t exactly an AI feature, but you’ll note that the title doesn’t limit me to AI future plans only. It also turns out that this isn’t much of a future plan. Puzzles are already done on the unstable branch, so I’ll use this section to tell you about the three kinds of puzzles.
The first is the least heavily-annotated sort, the one you might find on the hypothetical chess page of a newspaper: simply a rules string, a position string, and a description along the lines of ‘white to win in 4’. OpenTafl supports these with the new load notation feature: paste an OpenTafl rules string into a dialog box, and OpenTafl will load it. (There’s also a new in-game/in-replay command which can be used to copy the current position to the clipboard, ctrl+c and ctrl+v being nontrivial for the moment.)
The other two are closely related. They start with a standard OpenTafl replay, then use some extra tags to declare that the replay file defines a puzzle, and tell OpenTafl where in the replay file the puzzle starts. The puzzle author uses OpenTafl’s replay editing features to create variations and annotations for all of the branches of play he finds interesting, then distributes the file. When loading the file, OpenTafl hides the history until the player explores it. The two closely-related kinds I mentioned are loose puzzles and strict puzzles, the only difference being that loose puzzles allow the player to explore branches the puzzle author didn’t include, while strict puzzles do not.
OpenTafl has all the tools you need to author puzzles, although, at present, you will have to do your own position records. (Sometime down the line, I’d like to add a position editor/analysis mode, but today is not that day.) The README will have more details.
You can expect two or three puzzles to ship with the OpenTafl v0.4.4.0b release, along with all puzzle-related features.
Future evaluation function plans I mentioned before that there are some weaknesses in the current evaluation function, and that some changes will be required. I’m becoming more convinced that this is untrue, and that what I really ought to do is an evaluation function which is easier for humans to understand. The current evaluation function just places an abstract value on positions; the one I’d like to do uses the value of a taflman as an easy currency. In doing so, I can ask myself, “Would I sacrifice a taflman to do X?” Having that as a check on my logic would be nice, and would prevent me from making dumb logic errors like the one in the current evaluation function, where the attacker pushes pieces up against the king much too eagerly.
This may also require more separation in the evaluation function between different board sizes; sacrificing a taflman in a 7×7 game is a bigger decision than sacrificing one in an 11×11 game. I may also have some changing weights between the opening and the endgame, although, as yet, I don’t have a great definition for the dividing line between opening and endgame.
Anyway, that’s all theoretical, and undoubtedly I’ll be writing about it when I get to it, as part of the v0.4.5.x series of releases. In the meantime, though, I have plenty to do to get v0.4.4.0b done. I’ll be testing this one pretty hard, since it’s going to be the next stable release, which involves a lot of hands-on work. The automated tests are great, but can’t be counted on to catch UI and UX issues.
Thanks for joining me for Opentaflvecken! Remember, the AI tournament begins in about three and a half months, so you still have plenty of time to hammer out an AI if you’d like to take part. Hit the link in the header for details.
This isn’t exactly intuitive, but the person moving into a state for the third time is the person whose hand is forced. (Play it out for yourself if you don’t believe me.) Although it’s traditional to declare a threefold repetition a draw, I think it works better in tafl if the player making the forcing move is forced to make a different move or lose.
This is the second article in a series on AI improvements to OpenTafl. Read the first part here.
Welcome back! In the first article in this series, I talked about what was, essentially, groundwork. I did gloss over two rather large bugs in the course of that article, so I’ll give them a deeper treatment before I dive into the three topics I have planned for today.
First: I failed altogether to mention a bug that cropped up while I was writing continuation search, and which, in actuality, prompted my creation of the AI consistency test. I have a bit of code around for extension searches (that is, searches that begin from a non-root node), whose purpose is to revalue all of the nodes above it. I was calling that method much too frequently, even during the main search, which pushed child values up the tree much too quickly, and yielded incorrect alpha-beta values. The bounds converged too quickly, and I ended up cutting off search far too early, before the search had verified that a certain move was safe in terms of opponent responses. I ended up designing a miniature tafl variant, 5×5 with a total of four pieces all limited to a speed of 1, to diagnose the issue. As a game, it’s unplayable, but the game tree to depth 3 takes about 30 or 40 lines, and it’s easy to read the tree and see what’s happening. That’s what I did, and that’s how I found my problem.
Second: the incomplete tree search bug, which I covered in a small amount of detail in a footnote. This one dates back to the very beginning of the OpenTafl AI, and is likely the cause of most of its weaknesses and obvious misplays since then. As I said in the text and the footnote, it stemmed from the assumption that a partial search of, for instance, depth 6 was better than a full search of depth 5. The true trickiness of this bug is that a partial search of depth 6 is, indeed, often as good as a full search of depth 5. All alpha-beta AIs prefer to search the best moves first, so if OpenTafl gets a little ways into the tree, a partial search at depth 6 is good enough to match the full search at depth 51.
The really awful part of this bug, the one which made it the most inconsistent, was that OpenTafl doesn’t always manage to assign a value to every state when it’s out of time. The states have a magic number value marking them as having no evaluation: -11541. This value ended up in the game tree, and it’s a very tempting move for the defender. Subtrees the defender had not finished exploring would be chosen over subtrees it had, leading to inconsistent and incorrect behavior. The solution, as I mentioned in the previous post, was, when starting search to a new depth, to save the search tree to the previous depth. If the new depth doesn’t finish, OpenTafl uses the complete tree from the previous depth.
Time use planning That brings me quite naturally to my first new topic for today: time use planning. Getting time usage correct is tricky. Obviously, we want to search as deeply as possible in the main tree, but we also want to stop as soon as we know we can’t search to the next depth. Since we discard incomplete searches, any time spent on an unfinished search is wasted. Unfortunately, ‘can we search to the next depth?’ carries with it a good deal of uncertainty. OpenTafl now uses a few tricks to determine whether it should attempt a deeper search.
First, it better takes advantage of previous searches to a given depth. Concrete information is hard to come by for AIs, and ‘how long did it take me to do this last time?’ is pretty darned concrete2. Whenever a search is finished to a given depth, OpenTafl stores the time that search took in a table and sets the age of that data to zero. Whenever a search to a given depth fails, OpenTafl increments the age of the data for that depth. If the age exceeds a threshold, OpenTafl invalidates all the data at that depth and deeper.
When determining whether to embark on a search to the next depth, OpenTafl first checks the table. If it has data for the desired depth, it compares its time remaining to that figure. If there is no data, it synthesizes some. Obviously, we know how long it took to get to the current depth: we just finished searching to it. OpenTafl takes two factors into account: first, it’s hard to search to the next depth; and second, it’s harder to search to an odd depth than an even depth3. If going to an even depth, OpenTafl assumes it’ll be 10 times as hard as the previous depth; if going to an odd depth, OpenTafl assumes 20 times. These numbers are extremely provisional. Sometime down the line, I want to write some benchmarking code for various depths and various board sizes to generate some data to make those factors resemble reality more closely.
Second, OpenTafl reserves some time for extension searches. Horizon search oftentimes changes the end result of the evaluation, and so OpenTafl seems to play better when it has time to run. About 15% of the total think time for any given turn is set aside for extension searches.
Search heuristics #1: the history heuristic On to the heuristics! I implemented two for this release. The first, the history heuristic, is one of my favorites. Much like dollar cost averaging4 in finance, the history heuristic says something which is, on reflection, blindingly obvious about alpha-beta searches, but something that nevertheless is not immediately apparent. It goes like this: moves which cause cutoffs, no matter where they appear in the tree, tend to be interesting, and worth exploring early.
Consider the game tree: that is, the tree of all possible games. It fans out in a giant pyramid shape, ever widening, until all of the possibilities peter out. Consider now the search tree: a narrow, sawtoothed path through the game tree, approaching terminal states until it finally alights upon one. The search tree always examines a narrow path through the tree, because the full game tree is so overwhelmingly large. Since the search tree examines a narrow path, similar positions are likely to come up in many different searches, and in similar positions, similar moves are likely to cause cutoffs. Therefore, whenever a move causes a cutoff, we ought to keep track of it, and if it’s a legal move in other positions, search it earlier.
That’s about all there is to it: the bookkeeping is a little more complicated, since we have to do something to be sure that cutoffs high up in the tree are given as much weight as cutoffs lower toward the leaves (OpenTafl increments the history table by remainingDepth squared), but that isn’t especially important to understand the idea.
There are two variations on the history heuristic I’ve considered or am considering. The first is the countermove history heuristic. The history heuristic in its simplest form is very memory-efficient: you only need table entries; OpenTafl’s table entries are simple integers. Even for 19×19 tafl variants, the total size is less than half a megabyte. There exists a more useful expansion of the history heuristic sometimes called the countermove-history heuristic, which involves adding another two dimensions to the table: save cutoff counts per move and preceding move. This allows for a closer match to the situation in which the cutoffs were previously encountered, and increases the odds of a cutoff, but it turns out the inefficiency is too great in tafl games. Chess, with its more modest 8×8 board, can afford to bump the table entry requirement up to : it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case, , or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.
So I did some further reading on the subject, then came across another relation of the history heuristic: the relative history heuristic. It combines a plain history heuristic with something called the butterfly heuristic, which counts how many times a given position occurs in the tree. The relative history value of a state is its history heuristic value (the number of cutoffs it has caused) divided by its butterfly value (the number of times it has appeared in the tree). This makes the relative history heuristic a measure of the efficiency of a move: if a move appears ten times in the tree and causes ten cutoffs, it’s probably more interesting than a move that appears ten thousand times in the tree but only causes eleven cutoffs. I haven’t gotten around to it yet, but OpenTafl will probably include the relative history heuristic in a future AI release.
Search heuristics #2: the killer move heuristic The killer move heuristic is the other heuristic I implemented for this release. The killer move heuristic is a special case of the history heuristic5, and turns out to be the single greatest improvement in OpenTafl’s strength I’ve implemented to date6.
What is it, then? Simply this: for each search, it tracks the two first moves which caused a cutoff at a given depth, along with the most recent move to do so, and plays those first whenever possible. See? Simple. It calls for very little explanation, and I’m already at nearly 2,000 words, so I’ll leave you with this. See you later this week for the thrilling conclusion.
Advanced chess engines take advantage of this fact to search deeper: they do something called ‘late move reduction’, where the moves late in the move ordering are searched to a lesser depth, leaving more search time for the better moves (the ones earlier in move ordering). Move ordering in chess engines is usually good enough that that this works out.
It isn’t always useful, though. Depending on what happens on the board and how well the move ordering happens to work, relative to the previous search, the next search may be very fast (if it’s something we expected) or very slow (if it completely blows up our plan).
Even depths are usually small and odd depths are usually large, in terms of node counts relative to what you’d expect if the increase was linear. The mechanism of alpha-beta pruning causes this effect.
Dollar cost averaging makes the incredibly obvious observation that, if you put money into an asset over time, fixed amounts at regular intervals, you end up buying more of the asset when the price is low than when the price is high. Because of numbers.
Although the literature usually reverses this relationship: the history heuristic is normally referred to as a general case of the killer move heuristic, since the latter was used first.
In two ways: first, the version with the killer move heuristic plays the best against other AIs; second, the version with the killer move heuristic deepens far, far faster. The killer move heuristic is, in fact, almost single-handedly responsible for that faster speed to a given depth, going by my benchmarks. In brandub, for instance, OpenTafl reaches depth 6 in 2.5 million nodes without the killer move heuristic, and 1.3 million nodes with it. Searching killer moves first yields the best result, and moving anything ahead of them in the search order is non-ideal.
If you’re a regular reader over at Many Words Main, you’ll undoubtedly have thought that I’m some kind of bum, missing another update so soon. Not so! I’ve been very busy on other projects; very busy indeed. In a series of articles this week, I’ll be going through improvements I’ve made to OpenTafl’s AI. I’ll be releasing a stable version out of v0.4.3.x soon, which will feature the structural improvements I’ve made so far; next up will be puzzles in v0.4.4.x, then AI state evaluation improvements in v0.4.5.x.
So, what have I been up to? Well, let me open up my source control log, and I’ll tell you. Note I’m not reporting my progress in chronological order here: I present to you a natural-seeming order of features which bears little resemblance to reality, but which does make for a neater story.
Groundwork Before embarking on a project as fuzzy as AI improvements, I needed tools to tell me whether my changes were making a positive effect. I started with a simple one: a command which dumps the AI’s evaluation of a particular state. This lets me verify that the evaluation is correct, and it turns out (to nobody’s great surprise) that it is not. When playing rules with weak kings, the AI places far too much weight on having a piece next to the king. When playing rules with kings which aren’t strong (tablut, for instance), the AI still mistakenly assumes that placing one piece next to the king is the same as putting the king in check. An improvement to make for phase 2!
The next thing on the docket was a test. As I wrote about what feels like a lifetime ago, OpenTafl is a traditional game-playing artificial intelligence. It uses a tree search algorithm called minimax with alpha-beta pruning, which is an extension of the pure minimax algorithm. The latter simply plays out every possible game to a certain depth, then evaluates the board position at the end of each possibility, then picks the best one to play toward, bearing in mind that the other player will make moves which are not optimal from its perspective1. Alpha-beta pruning extends minimax by taking advantage of the way we search the tree: we go depth first, exploring leaf nodes from ‘left’ to ‘right’2. As we move to the right, we discover nodes that impose bounds on the solution. Nodes which fall outside those bounds need not be considered. (The other article has an example.)
Anyway, the upshot of the preceding paragraph is that, for any given search, minimax and minimax with alpha-beta pruning should return the same move3. Previously, I had no way of verifying that this was so. Fortunately, it turned out that it was, and out of the whole endeavor I gained an excellent AI consistency test. It runs several searches, starting with all of OpenTafl’s AI features turned off to do a pure minimax search, then layering on more and more of OpenTafl’s search optimizations, to verify that none of the search optimizations break the minimax equivalence4.
Extension searches Strong chess engines do something called extensions: after searching the main tree to a certain depth, they find interesting positions among the leaf nodes—captures, checks, and others—and search those nodes more deeply, until they become quiet5. OpenTafl does something similar, albeit on a larger scale. After it runs out of time for the main search, it launches into a two-stage extension search.
First, it attempts to deepen its view of the tree overall, a process I’ve been calling ‘continuation search’. Rather than clear the tree and start again, as OpenTafl does on its other deepening steps, continuation search starts with the tree already discovered and re-searches it, exploring to the next depth and re-expanding nodes. This process is much slower, in terms of new nodes explored, than a new deepening step, but as you’ll recall, deepening goes from left to right. A new deepening step discards useful information about the rightmost moves, in the hopes of discovering better information. Continuation search assumes that we don’t have the time to do that well, and that a broad, but not exhaustive, search to the next depth is more correct than half of a game tree6.
Continuation search takes time, too, though. It has to muddle its way down through the preexisting tree, potentially expanding lines of play previously discarded, before it gets to any truly new information. When there isn’t enough time for continuation search, the AI does something I’ve been calling horizon search, which resembles the traditional extension searches found in chess engines. The AI repeatedly makes deeper searches, using the end of the best nodes as the root. Frequently, it discovers that the variation it thought was best turns out not to be: I’d put it at about half the time that horizon search runs, discovering some unrealized weakness in the position that the evaluation function did not correctly account for.
But then again, it isn’t the evaluation function’s job to predict the future. The history of traditional game-playing AI is one of a quest for greater depth; a simple evaluation function and a deep search usually gives better results than a heavyweight evaluation function and a shallow search. With this philosophical point I think I will leave you for now. I have at least one more of these posts running later in the week, so I’ll see you then.
1. Hence minimax: one player is traditionally known as max, whose job it is to maximize the value of the position evaluation function, and the other is known as min, whose job is the opposite. The best move for max is the move which allows min the least good response. 2. Or whatever other natural ordering you prefer. 3. Or a move with the same score. 4. Since minimax is known to produce the optimal move from a given situation, any search which is not the same as minimax is no longer optimal. It turned out that, depending on the search optimizations, moves might be considered in a different order, and in case of identical scores, the first one encountered would be selected. The test runs from the start, so there are eight symmetrical ways to make the same move, and some searches came up with mirrored or rotated moves. Out of the bargain, I got methods to detect rotations and mirrors of a given move, which will serve me well for the opening book and the corner books I hope to do down the road. 5. Another point where chess AI developers have an edge on tafl fans: there’s more research on what makes for a quiet chess position (one where the evaluation is not likely to dramatically shift) than there is for tafl positions. 6. This was the source of a particularly pernicious bug, because it evaded most of my tests: most of the tests had search times just long enough to get near the end of the tree for a given depth, and the best move occurred at the start of the search in the rest. Continuation search also caused another bug, in response to which I wrote the AI consistency test. (I told you I wasn’t going in chronological order here.) That one was all my fault: I have a method to revalue the parents of a node, which is important for the next kind of search I’ll be describing. I was calling it after exploring the children of any node, propagating alpha and beta values up the tree too fast and causing incorrect, early cutoffs (which meant that the AI failed to explore some good countermoves, and had some baffling weaknesses which are now corrected).
Undoubtedly the release number will continue to increment as I find and fix little bugs in my work on the AI improvements branch. Either way, v0.4.2.x is now the stable branch, carrying with it two major features: variations in replays, and some additions to the stable of rules.
First, variations: the headline feature for v0.4.x, variations provide players the ability to play out alternate histories in replay mode. These alternate histories can be saved and loaded, as well as annotated (and, annotations now have a handy new in-game editor for ease of production).
Second, rules: I finally got around to implementing the last two rules preventing OpenTafl from playing almost all known tafl variants. Not coincidentally, OpenTafl now supports every rule supported by PlayTaflOnline.com, so the bot player there can compete on every front. Poorly.
That brings me to my last point for today: AI improvements. What’s on the list? Well, I have a few things on my list.
First thing’s first: I have to characterize OpenTafl’s particular failings. The ones I can most easily fix rest in the evaluation function. If the evaluation function provides inaccurate evaluations of board states, then all the rest—heuristics and fancy pruning alike—rests on an unsteady foundation. The analysis engine feature aids me in this quest. My workflow for this initial phase goes like this: I play a game against the AI, using the analysis engine to feed me the AI’s moves. When the AI makes a move which is obviously bad, I go to the replay, then tell the analysis engine to dump its evaluations for the states in question. By comparing those evaluations with evaluations of the move I would prefer, I can begin to see what the AI sees.
I’ve already made two interesting discoveries regarding AI weights and preferences. First, it places far too much importance on guarding or attacking the king, to the point that the attacker AI will happily sacrifice piece after piece if only it puts the king in ‘check’. Second, flowing out of the first item, it has a badly inaccurate view of what constitutes threatening an opposing piece. When it decides to threaten an enemy piece, it will happily do so by moving one of its own pieces into a position where it can immediately be recaptured. Oops.
So, once I’ve made changes to fix those mistakes, how do I verify that I’ve made a positive difference? I play the AI against old versions. Thankfully, building older versions of OpenTafl is trivial. (If you’ve been following development, you’ll no doubt have noticed that there’s a Mercurial tag for every release.) I have a little tool which is intended to do Elo ratings for chess clubs, but which will serve to do Elo ratings for OpenTafl versions just fine. This helps quantify not only whether a version is better than another version, but by how much.
Once I have the evaluation function a little more settled, I can move onto some extra heuristics. I have two in mind for the moment: the killer move heuristic, and the history heuristic (or some related heuristic). The killer move heuristic is the more promising one. It assumes that most moves don’t change the overall state of the board too much, and there are likely to be, at a given depth in the tree, only a few plausible moves to push the evaluation in your direction. Therefore, if any of those moves are possible at that depth, the AI should try them first.
The history heuristic is more complicated. There are three variations I’m considering. First, the straight history heuristic, which orders moves by how often they’ve caused a cutoff. This prefers, in the long run, making moves which have been good elsewhere in the tree. Straightforward, compared to the others.
Second, the butterfly heuristic, which orders moves by how often they occur anywhere in the tree. This prefers making moves which are frequently considered. This one is a little more subtle. Alpha-beta search, by its very nature, ends up searching only the most interesting moves, pruning away the rest. The butterfly heuristic, by tracking moves which turn up a lot, is essentially tracking which moves are more interesting.
Finally, the countermove heuristic, which tracks which moves are the best responses to other moves, and weights moves matching the known good countermove more heavily. This one requires very little explanation.
So, in the next month or two, I expect the strength of OpenTafl’s AI to improve considerably. Stay tuned!
The headline feature in OpenTafl v0.4.x is playable variations: that is, when viewing a replay, you’ll be able to say ‘variation a1 a3’ to create a new branch in the history, which can be added to, viewed, navigated, and commented upon like any other branch. It turns out this is, to put it mildly, non-trivial. Before I go into why this is, I’d like to talk for a few hundred words about why this feature excites me.
In short, this feature is the last feature before OpenTafl hits feature-completeness, relative to engines for other abstract strategy game engines. Other engines include it because it’s a useful tool for teaching and review; OpenTafl will be no different. I find teaching, especially, to be important. At present, available tafl commentaries remark only on the principal line of play. If they touch on variations, they do so only in passing. Understanding why a variation is a bad idea is all but a requirement for higher-level play, and providing room for commentators to make those comments is therefore a requirement for OpenTafl.
The usage in which I’m most interested, however, is puzzles. A puzzle is nothing but a branching commentary in which it is impossible to read ahead, and OpenTafl should support that pretty easily. I have a few tafl puzzles in mind already, thanks to interesting situations from my approximately-weekly game, which I hope to package with the first release of v0.4.x. To fulfill the ‘impossible to read ahead’ requirement, I’ll be adding an allowable tag to the saved game file format. When set, OpenTafl will suppress use of the ‘history’ command when viewing a replay.
Both of these usages presuppose a community of OpenTafl-literate commentators and puzzle authors, and the current setup for editing commentaries is not what you would call user-friendly. I plan to stick in a quick-and-dirty comment editor, a big text box you can use to define the comment for a particular state.
There. That covers, approximately, the list of features and their justifications for this release. On to the depressingly practical bits. How?
It turns out to be a tricky problem. I did not write the early versions of OpenTafl with an eye toward a tree structure for game histories. Since the GameState object, the standard representation for a tafl position in OpenTafl, is already a heavy object and already used in the AI, I didn’t want to add anything further to it. OpenTafl already uses a ReplayGame object to overlay the basic Game object during replays, so the natural thing to do was extend GameState to ReplayGameState, and put all the replay-related data and functionality into ReplayGameState. This solved the first problem: where to store the data? It revealed another: how to reference it?
It turns out that the problem of naming branches in a tree is also not altogether trivial, at least as far as the scheme goes. Fortunately for you, OpenTafl user, you won’t have to worry about figuring out how it works; replay mode will name each state for you, and you can specify which one you want to jump to. I, however, had to do the heavy lifting.
In replay mode, each state now has a specific name. The first state (more accurately, the first move) is state 1a. The next move is state 1b. (In berserk tafl, you might see a 1c or a 1d.) Those two (or more) moves compose the first turn. Turn 2 comprises 2a and 2b. Easy so far, right? Let’s dive into a more complicated example. Say you start a game, enter replay mode, and type ‘variation a4 a2’. You’ve now moved off of the beaten path: you’re in a variation. The state you’re in is now called 1a.1.1a.
Whoa. What’s going on?
This is an OpenTafl variation address. We’ll read them from right to left. First, the last element: 1a. That means this is the first turn of a new branch of play, and this is the first move therein. Next, the middle element: 1. That means that this is the first variation off of the state to our right. Finally, the first element: this variation replaces move 1a. A shorter reading is, “the first move of the first variation off of move 1a.” If you make further moves in that variation, they’re called 1a.1.1b, 1a.1.2a, 1a.1.2b, and so forth. For the sake of clarity, we’ll start some of our later examples from 3a, and its first variation: 3a.1.1a. (The first move in the first turn of the first variation off of the first move of the third turn.) Got it? Cool. We’ll try a harder one.
7b.3.1b.2.4a.1.1b. (I said it would be hard.)
Remember, right to left. This is (1b) the second move in the first turn of (1) the first variation off of (4a) the first move of the fourth turn of (2) the second variation off of (1b) the second move in the first turn of (3) the third variation off of (7b) the second move of the seventh turn of the game.
Those of you quicker than me will have noticed something a little odd. Remember how I said the first move following 3a.1.1a is 3a.1.1b? Well, what happens if we make a variation off of 3a.1.1a? It turns out that it’s 3a.1.1a.1.1b1. Remember, 3a refers to the first move. We can replace 3a with a new move, named 3a.1.1a. If we want to branch from 3a.1.1a, though, the next state is not 3a.1.1a.1.1a: we’ve already replaced 3a, the first move in the turn. What we want to do is replace the next move in the turn: 3a.1.1a.1.1b. The perhaps-unwanted side effect is that 3a.1.1a.1.1b and 3a.1.1b are siblings: both occur two moves after 3a. A little odd, but necessary.
That about covers the problem of addressing, which is the first problem I’ve addressed. The hard part isn’t generating variation states: the hard part is storing them and finding them by a human-readable address. (I won’t insult you by saying that it’s easy.)
There are other problems, of course: how to present this functionality to the user. I haven’t done that yet. Nor have I done saving and loading of games with variations. In fact, all of this work, which comes to about a week of evenings and 1000 lines of code, has knocked precisely one item off of my v0.4.x to-do list. Fortunately, I think I’ve done at least one of the hard things first. (Loading variations is, admittedly, going to be a huge pain.)
Anyway, you can expect more posts down the line. For now, I have some tests to write.
1. I use that phrasing—’it turns out’—advisedly. Because OpenTafl stores games as a series of board positions, rather than a series of moves, the indexing is all weird. For instance, the state labeled 1a is the starting position, and ‘1a’ refers to the move which exits the starting position. The entire main line of play is addressed in the same way: a state’s address refers to the move which exits that state. You no doubt see the failing here: a variation is a second way to leave the state, and OpenTafl’s not about that kind of ambiguity2. Therefore, so that we can label every move in the game, addresses on variation states have to refer forward, to the move which enters them. The numbering is different between when you branch from 1a (becomes 1a.1.1a) and when you branch from 1a.1.1a (becomes 1a.1.1a.1.1b). Fun3. 2. Here we attribute to principle what is, in reality, just incompetence. 3. In the process of writing this blog post, I’ve discovered and fixed at least three or four inconsistencies in the naming scheme. Rough.
Releasing today is OpenTafl v0.3.3.2b, most likely the final version of OpenTafl in the v0.3.x series. How far we’ve come in the…1 month and a half since these releases kicked off2. After a few false starts, I’ve decided upon this set of features as the final, stable set for v0.3.x.
Beyond the obvious (network play and other associated features), OpenTafl has seen some incidental UI, AI, and framework improvements. Nothing major you haven’t already heard about, so I won’t go into too much depth here. You’ll find that the server login dialog is a little more informative now, and that network games no longer ask for a password when one is not required. You’ll also find (since my last post) that network clients can load saved games, large boards have some extra features (try the ‘info’ command!), network hosts can disallow replay or analysis, and that several network bugs have been fixed. Hit up the README for more information there.
From here out, excepting bugfixes to v0.3.3.2b, my work will be on two new branches. v0.4.x will likely be a long-lived series of releases, since it’ll have both a big-name feature (playable variations) and a long, iterative process of improvements (the AI). Stay tuned for news. I have a pretty good idea of how I want to do playable variations, and a post on that, going from design goals to implementation plans, should be coming soon.
1. Picture me consulting the README. 2. It’s even more dramatic when you consider that, as a public project, OpenTafl is now only about seven months old, and has grown at a rate of nearly 3,000 lines of code per month.
A new version of OpenTafl is out. Happily, this one doesn’t break network compatibility! As usual, the README has full details, but here are the highlights.
First off, performance improvements! The micro-optimizations I wrote about are now in the release. This brings OpenTafl’s speed up to the standard set by v0.2.5.3b. You may also notice enhanced responsiveness from the UI, which comes from updates to the Lanterna UI library.
Speaking of which, updates to said library have also resolved issues with OpenTafl drawing in native terminals. Use the –fallback switch to run OpenTafl in pure ANSI terminal mode. Handy if you’re on a server or something. Changes in Lanterna also required a little bit of rewriting on the Swing front; the upshot is that font size is now configurable.
Finally, I took care of a few large-board issues: the row indices now print correctly for boards larger than 9×9. In the same vein, alea evangelii (19×19 tafl) is now available, and I can feel a 19×19 tafl theory post coming soon, I think.
Tonight, OpenTafl saw its first micro-optimization!
Let me start from the beginning, though. OpenTafl has a static Coord type, which holds precalculated information about coordinates: what their index is, where they are on the board, and so on. Before network mode, OpenTafl updated the Coord type at the start of each game to correspond to the board size for the selected rules variation.
Astute readers may have noticed the problem. On the server, multiple games may be ongoing, on boards of different sizes. The Coord object should therefore have all the information required for any size of board. The network mode patches included a rewrite of Coord to hold all the information at once, indexed in maps by board size. This solved the problem, but yielded about a performance hit of about ten to fifteen percent. (Obviously, the Coord code paths come up a lot.)
At first, I wasn’t going to worry about it. Then, I had a little downtime this afternoon and decided, “Well, I’m not going to get anything else done right now.” Firing up the old profiler, I found a hotspot to work on.
When exploring the game tree, OpenTafl caches information about how pieces can move. (Calculating it out every time is computationally expensive, or at least more computationally expensive than can be justified doing it every time.) Clearing this cache involves zeroing an array. The usual way to do this is to loop over the array and set everything to zero. (Whether you choose a library function or write it by hand, this is usually what happens.) Unfortunately, that ‘reset’ function, according to the profiler, took longer on aggregate than any other single operation, including such expensive calculations as shieldwall detection and surrounding victories. This would not do.
The solution? Well, although Java’s library methods for array filling do not use native code memory copying, Java’s library method for copying one array to another does. The titular micro-optimization, therefore, was to set the first slot of the array to the desired value, then copy that to the second, then copy those two to the second two, then copy those four to the next four, and so on until the array is fully filled. Since this works directly on system memory, it turns out to be faster.
How much faster? To answer that question, I wrote a little benchmark function for OpenTafl, which runs a 30-second brandub search, a 30-second tablut 9×9 search, a 60-second Copenhagen search, and a 60-second Tablut 15×15 search, which verified the 10-15% slowdown from pre-network to post-network. Fortunately, the move cache optimization yielded a speedup of about 15%, bringing us right back to where we were before. Et voila.


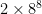 : it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case,
: it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case, 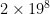 , or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.
, or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.