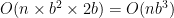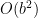In my last tafl post, I remarked that I’m nearing the end of my current OpenTafl sprint. Now, it’s wrapped up. Here’s what I finished:
Write about 70% of a new evaluation function. It’s designed to easily accommodate tweaks and modifications, which will undoubtedly be required as I learn more about the game and uncover positions that the current function evaluates incorrectly.
Move OpenTafl into its own repository, so I can publish the source.
Package and test OpenTafl for binary distribution.
Rewrite exploration to generate and sort moves prior to generating states.
All three of these are done, and OpenTafl downloads and source releases can be found at the Many Words Softworks site for OpenTafl. Play and enjoy. For questions, comments, or bug reports, please leave a comment, or drop me an email. (My contact information is in the About section at the main page.)
Here’s what’s on the list for the next sprint:
Support for easy position entry. This will require creating some sort of short-form positional notation, akin to FEN from the chess world.
External AI support, a la several chess engines. This will require defining a protocol by which OpenTafl can communicate with an external AI, including communicating things like the rules of the variant in question.
Partial time control, so that OpenTafl can be limited to a certain number of seconds per turn.
Some search improvements and tweaks. The prior three features are important stepping stones to this one; they’ll let me test OpenTafl against itself by quick-play tournaments, and therefore verify what sort of impact my changes are having.
As you can see, the next sprint is less about the nitty-gritty AI research and more about foundational work in developing OpenTafl as an engine for future AI research—my own and others. Ultimately, that’s a more important task.
Having spent quite a lot of time on another code project, it’s high time I got back to a little tafl.
Remember where we left off: board states represented as arrays of small integers, and taflman objects inflated as needed during game tree search. It turns out that inflating and deflating taflmen is also a potential source of slowness, so I went ahead and removed that code from the game. (It also greatly simplifies the process of moving from turn to turn.) Wherever I would pass around the old taflman object, I now pass around a character data type, the sixteen bits I described in the previous tafl post.
This revealed two further slowdowns I had to tackle. The first, and most obvious, was the algorithm for detecting encirclements. For some time, I’ve known I would need to fix it, but I didn’t have any ideas until a few weeks ago. Let’s start with the old way:
for each potentially-surrounded taflman: get all possible destinations for taflman for each destination: if destination is edge, return true return false
Simple, but slow. In the worst-case scenario, each taflman has to consider every other space on the board, and look briefly at every other space from each rank and file (where n is the number of taflmen and b is the board dimension):
I was able to cut this down some by running an imperfect fast check: if, on any rank or file, the allegedly-surrounded side has the taflman nearest either edge, that side is not surrounded. That had implications for a better algorithm, and sure enough, I hit on one.
list spaces-to-explore := get-all-edge-spaces list spaces-considered := [] for space in spaces-to-explore: add space to spaces-considered get neighbors for space not in spaces-to-explore and not in spaces-considered for each neighbor: if neighbor is occupied: if occupier belongs to surrounded-side: return false else continue else: add neighbor to spaces-to-explore return true
More complicated to express in its entirety, but no more difficult to explain conceptually: flow in from the outside of the board. Taflmen belonging to the surrounding side stop the flow. If the flow reaches any taflman belonging to the allegedly surrounded side, then the allegedly surrounded side is, indeed, not surrounded. This evaluation runs in a much better amount of time:
Astute readers might note that, since the board dimension is never any larger than 19 at the worst, the difference between a square and a cube in the worst-case runtime isn’t all that vast. Remember, though, that we need to check to see whether every generated node is an encirclement victory, since an encirclement victory is ephemeral—the next move might change it. Running a slightly less efficient search several hundred thousand to several million times is not good for performance.
I found another pain point in the new taflman representation. The new, array-based board representation is the canonical representation of a state, so to find a taflman in that state, the most obvious move is to look through the whole board for a taflman matching the right description. Same deal as with encirclement detection—a small difference in absolute speed makes for a huge difference in overall time over (in this case) a few tens of millions of invocations. I fixed this with a hash table, which maps the 16-bit representation of a taflman to its location on the board. The position table is updated as taflmen move, or are captured, and copied from state to state so that it need be created only once. Hashing unique numbers (as taflmen representations are) is altogether trivial, and Java’s standard HashMap type provides a method for accessing not only the value for a given key, but also a set of keys and a set of values. The set of keys is particularly useful. Since it’s a canonical list of the taflmen present in the game, it saves a good bit of time against looping over the whole of the board when I need to filter the list of taflmen in some way.
Those are all small potatoes, though, next to some major algorithmic improvements. When we last left OpenTafl, the search algorithm was straight minimax: that is, the attacking player is the ‘max’ player, looking for board states with positive evaluations, and the defending player is the ‘min’ player, looking for the opposite. Minimax searches the entire game tree.
Let’s look at an example, a tree of depth 3 with max to play and a branching factor of 3, for 9 leaf nodes. The leaf nodes have values of 7, 8, and 9; 4, 5, and 6; and 12, 2, and 3. We can express the minimax perspective on this tree mathematically:
That is to say, max makes the move which gives min the least good best response. Remember, though, that we search the tree depth-first, which means that in the formula above, we move from left to right. This leaves us with some room for cleverness.
Consider this:
Does it matter what the numbers at x, y, and z are? No: by that time, we’ve already established that the subtrees in which they appear (with best possible values 4 and 2) are worse than the first subtree (with known value 7). Therefore, we can stop exploring those subtrees. This is known as ‘pruning’.
Pruning is good, because, when done correctly, it saves us work without dropping good moves. Alpha-beta pruning, the kind described above, is known to produce identical results to minimax, and, in the ideal case, can search twice as deep. (So far, it’s only given me one extra ply, though; the case isn’t quite ideal enough for more.) Other kinds of pruning may find their way in later, and will take some more careful thinking to avoid pruning away potentially good branches.
What is the ideal case, then? We want to explore the best moves first. A cursory examination of the example case above provides the reasoning. If we explore the subtrees in opposite order, we can do no pruning, and we get no speedup. This presents us with a chicken-and-egg problem: if we could easily and programmatically determine which moves are good, we wouldn’t need to bother with variants on full-tree search at all.
Fortunately, the structure of a tree gives us an easy out. Most of the nodes in any given tree are at the bottom. Consider a simple example, with a branching factor of two. At the first level, there’s one node; at the next, two nodes; at the third, four nodes; and at the fourth, eight nodes. In every case, there are more nodes at the deepest level than at all the levels above combined. The difference becomes more pronounced with greater branching factors: a tree with a branching factor of 30 (which approximates brandub) has a distribution of 1/30/900/27,000. So, it follows that the large majority of the work in a game tree is expanding the game states at the target search depth, and evaluating those states; the work higher up the tree is almost trivial.
Take that and add it to this claim: the best move at any given depth is likely to have been one of the best moves at the immediately prior depth, too. We can use those facts together to figure out the best ordering for our moves at our target depth: search to the depth prior, keep track of the best moves at that depth, and search them first. This approach is called ‘iterative deepening’: generally, you start at depth 1, and use results from previous levels to order each node’s children. OpenTafl accomplishes this with a structure I’m calling a deepening table, which is generated for each . The deepening table is a list of maps, one per depth. The maps relate a position hash to an evaluation done at its depth. On each deepening iteration, the exploration function generates successor states, then sorts them according to the data stored in the deepening table before exploring further. (There’s some easy performance on the table here—since creating a full-on successor state is a non-trivial operation, I can probably buy myself some easy speedup by generating moves alone, sorting those based on the positional hashes which would result from making those moves, and only generating states immediately before exploring them. This would probably save a good bit of time by never generating states which would have otherwise been cut off by alpha-beta pruning.)
Implementing the deepening tables put me on the scent of another major optimization, the transposition table. A transposition table stores values for previously-visited states, along with the depth each state was previously searched to. (If we’re searching six plies deep and previously encountered a state at depth four, that state was only searched to a depth of two. If we encounter the same state at depth two, then if we use the cached value, we’ve left two plies of depth on the table.) Hits in the transposition table early on in the search save us expanding whole subtrees, which yields many fewer node expansions required per search, and lets us reach deeper more easily.
The transposition table, since it persists through the entire game, must be limited in size by some mechanism. OpenTafl’s transposition table is an array of Entry objects, with a fixed size in megabytes. The array is indexed by positional hashes, modulo the size of the table. When indices collide, OpenTafl decides whether to replace the old value based on its age (older values are more readily discarded) and the depth to which it is searched (deeper searches are kept, if both are equally as fresh).
That brings me to the end of another marathon tafl post. Stay tuned for another one—probably a much shorter one—in the not-too-distant future, as I wrap up work on this sprint of OpenTafl, with an eye toward the first public code and source release.
Let’s have a little fun with some military theory. How do we define a squad?
A squad can be thought of in a few ways. We tend to think of a squad as a basic combat unit, commanded by a single man. Working out span of command issues is a royal pain. Since we’re trying to keep this firmly academic, and since we don’t have a handy lab to test things, we’ll use a simple litmus test: the sports field. For example, American football tends to put eleven men on the field at a time per side. We’ll neatly sidestep any attempt to be dragged into discussions of a heap problem here, and simply check for a sport example as we work on numbers.
Our sports litmus test provides some nice options for us. Since this a mechanized squad, it’s important to think about the parent vehicle as well. Most IFVs hold six or seven men. We’ll take the lower figure, being cynical sorts. It’s also not especially clear what the CV9035’s capacity is; this tends to vary from six to eight based on configuration. Regardless, our first thought might be to take the squad as the sum of the dismounts of the vehicle and the crew needed by the vehicle, which gives us a size of nine or ten. This passes our sports litmus test. However, it’s been tried and rejected by several real-world armies. The issue seems to be that the dismount element is too small. We cannot guarantee that we’ll always have the vehicle to work with the dismount team, and given the realities of the battlefield (casualties, people on leave, casualties, people off on training assignments, casualties), the dismount team is likely to be quite a bit smaller in practice. We’d have to combine dismount teams across vehicles anyway, so we may as well formalize the organization and give the men practice at working together and rapidly forming up from the dismount.
With that settled, we come back to the question of how big the squad should be. Let’s look at some historical examples, bearing in mind we’ll have to fit them into to vehicles. The United States Marine Corps squad is probably the most successful, remaining a standard 13 men for over 70 years. This squad is comprised of three fireteams of four men plus one squad leader. This is also the largest squad that I’ve found good historical record of, so we’ll take it as a rough maximum. Give or take one or two is probably ok, since we’re trying to avoid stupid pedantry about heaps, but much bigger is probably a bad idea if we’re still going with the squad paradigm of a single commander. The US Army has had a couple squads since the Second World War. Until the late seventies, the US Army squad was eleven men: one squad leader plus two fireteams of five men each. Afterwards, the squad was revised downward to nine; the fireteams now consisted of four men. This reduction in size may have been to deal with reduced manpower in the wake of the end of conscription, or to better fight in vehicles.
Both the US Army and the USMC favored keeping the squad leader separate from the fireteams he commands, but not all armies saw it that way. Both the British and the Germans favored keeping the squad leader as an organic component of one of the fireteams. He functions as both squad leader and fireteam leader. The British Army of World War II featured a ten-man squad, though this was before they hammered out the four man fireteam concept. It has since been reduced to eight, again featuring two fireteams of four. During World War II, the Wehrmacht moved from a twelve man squad to a ten and eventually a nine man squad for reasons of dwindling manpower. They tended to feature an asymmetric, ad hoc grouping of machine gun(s) and assistant gunner(s) in one team and the riflemen in another. But we can note that most nations by now have moved to the four man fireteam, and then the squad is some multiple thereof. The Germans also use eight man squads now, usually.
Why the four man fireteam? Well, we might think about how small a team we can get in combat and be useful. One man is entirely too vulnerable. We can start with two, but we can quickly see that three men is a much more useful standard. More support, ability to work with the vast majority of crew served weapons, plus the ability to take a casualty and still be at least semi functional. Several forces have used the three man ‘cell’ as the basis of squad organization. The problem is that it doesn’t take casualties well, and will force frequent reorganization. Four men teams work better in terms of absorbing inevitable casualties, and this is borne out by the historical record. The Marine squad was originally a copy of the circa 1938 Chinese organization of a leader and three cells of three, but inevitable combat casualties forced them to add a fourth man to each team. More than four likely causes more difficulties for low-level, often improvised span-of-command, and doesn’t quite add enough to justify the trouble and logistical expense. The Rhodesian Light Infantry usually used four man squads, since this was all they could fit on their Alouette helicopters. They found this adequate for single taskings and tended not to remain in the field after multiple contacts, so the lack of casualty resistance wasn’t an issue. Fine for COIN, perhaps, but less than ideal for, say, Guadalcanal.
The question now becomes two or three fireteams, and whether we want the squad leader to be a part of a fireteam. We can see a generally downward trend in squad size, with the exception of the USMC squad. The USMC is still a light infantry force, which is to say they march to combat. Most other armies have to deal with some proportion of troops that have to fit in APCs or IFVs for their transport , and armored vehicle capacity isn’t very good, especially once you factor in all the equipment modern have and the body armor that they wear. So let’s return vehicle capacity.
We’ve opted for the CV9035. The CV90 family is highly configurable as we’ve seen. One of the choices is how you configure the interior. Depending on choices for internal layouts, seating arrangements of six, seven, or eight are available. We’ll make whatever internal stowage or secondary systems sacrifices are needed to have eight dismounts, which neatly dovetails with a pair of standard, four-man fireteams. Given that the CV90 is about as big as a PzKpfw VI Tiger I, I don’t see that too much would need to go to accommodate the seats. As we’ll soon see, this means we can have fewer vehicles per platoon, which is a nice win for cost and maintenance. We’ll settle for strapping things to the outside if we must.
Eight man squads also clearly pass our sports rule of thumb check. One fewer than the baseball grouping of nine is very good. From a bureaucratic/cohesion standpoint, we might want to count the IFV and vehicle crew as part of the squad, and expect the dismounts to help with maintenance. In this case, we have eleven men in the squad, which is the requisite men on the field for American football. We’re good regardless of how we break this down.
Accepting an eight-man (dismount) squad, with integrated squad leader, would let us have three squads in a platoon with only three vehicles, rather than the four that the US Army mechanized platoon has for its nine-man squads. We could conceivably go up to four squads, but that’s a more unwieldy platoon for the young lieutenant. As it is, he can opt to give each squad an IFV, or group the IFVs together in a sort of light tank platoon. Here, he has four elements to command, though he might also opt to reorganize the nominally eight man squads, perhaps into two twelve-man units. Squad organization is mostly bureaucratic anyway. Lieutenants are expected to be flexible and aggressive if nothing else.
Later we’ll get to platoon and squad level equipment tables.
In the past, I’ve written about the problem of tafl AI mainly in terms of its theoretical challenges. Those challenges remain, but can be mitigated with clever algorithms. (That work is in progress.) The theoretical challenges, however, are only half of the issue—and, I’ve been thinking, they may not even be the big half.
Consider go AI. Go is widely regarded as computationally intractable for traditional AI techniques. As such, go AI fits one of two patterns: probabilistic and machine-learning approaches, and knowledge-based approaches. The former is interesting in its own right, but doesn’t bear on our problem. OpenTafl is not currently built with an eye toward probabilistic or machine-learning techniques1. Rather, we’ll look at the more traditional school of go AI. The knowledge-based approach takes expert knowledge about go and applies it to traditional AI techniques. Rather than exhaustively searching the game tree—something which becomes intractable very quickly, given the branching factor in go—a knowledge-based AI applies heuristics and rules of thumb at each board state to prune uninteresting branches, and reduce the branching factor sufficiently so that the pruned tree can be explored to a useful depth.
How does one get this knowledge? One plays go. Knowledge-based AIs are generally written by good go players who are also programmers. The player/programmers use their domain knowledge to design sets of guidelines for deep exploration which work well, and to decide which sorts of starting states each guideline can be applied to. Though chess AIs deal with a much more tractable tree-search problem, they also use some knowledge-based augmentations to increase depth around interesting series of moves. Chess knowledge is a little different than go knowledge, however; there are formal answers to a large number of chess questions. Piece values are well-known, as are the pawn-equivalent values of certain important board control measures like pawn structure and rooks on open ranks.
Both of the best-studied games in AI, then, use some domain knowledge to push the search horizon deeper, whether by encoding the sorts of heuristics a certain player uses, or by encoding formal knowledge about the game itself. Chess goes further by packing in databases of solved endgames and good openings, which increases the effective search depth at interesting parts of the game2. Let’s think about applying these tactics to tafl.
Can we work like we might in go, using expert player knowledge to inform an AI? Yes, technically, but there’s a huge obstacle: tafl games are a tiny niche in the global board game market. My rough estimate is that there are perhaps a few thousand serious players. I wouldn’t be very surprised if fewer than ten thousand people have ever played a full tafl game, whereas I’d be highly surprised if more than a hundred thousand have. Writing about tafl tactics is therefore in its infancy5. There’s very little in the way of reading material that an average player like me could use to develop more in-depth knowledge, and, as far as I know, there are no other tafl players with a computer science background who are working on the problem of tafl AI.
Can we work like we might in chess, then? The answer here is simple: a categorical no. The amount of formal knowledge about tafl games is even smaller than the amount of non-formal knowledge about them6. Endgame databases infeasible7>, and nobody has carried out study of good openings for various taflman arrangements on boards of various sizes. Beyond that, we can’t formally answer questions about even the most elementary pieces of tafl strategy. In chess, I can say with some certainty that a rook is worth about five pawns. Given that favorable board position and pawn structure are only worth about a pawn or a pawn and a half, if I’m going to trade my rook for good board position, I should try to get at least a minor piece (a knight or bishop) and a pawn out of the bargain, too. Tafl is a much more positional game, which makes questions like this harder to pose, but an analogue might be, “Is it worth it to move my king from c3 to make a capture and set up another, or should I hold the good position?”
Here’s another question we don’t have a good answer to: what is the value, in terms of win percentage, of an armed king captured on four sides (a strong king) against an armed king captured on two (a weak king)? Certainly, we know that an armed king is an extremely powerful piece in material terms. The king’s side has a nearly 2-1 disadvantage in material, but in many common 11×11 variants with a strong armed king, he wins at about a 2-1 rate in games between expert players8. On the other hand, 9×9 Sea Battle, a variant with an unarmed strong king escaping to the edge and no hostile central square, is still biased about 2-1 in wins toward the king’s side. On the other other hand, 9×9 Tablut, the variant on which all other variants are based9, features an armed strong king with a corner escape and a hostile central square, and is approximately as evenly balanced as chess. We can’t even answer questions about a king’s worth, or about the shift in balance provided by various rules tweaks.
So, the formal approach, for now, is out, and we’re left with knowledge-based approaches. This presents me with a variant of the chicken-and-egg problem. I have one chicken (a tafl engine), but I lack a rooster (a strong AI) with which to produce a viable egg (answers to interesting questions). The task before me is this: use my mad scientist’s toolkit (my brain, my passing familiarity with tafl games) to cobble together some sort of Franken-rooster that get my chicken to lay eggs, which will in turn produce less monstrous roosters.
Leaving aside tortured metaphors, it’s relatively easy to get an AI to a moderate level of play. All you have to do is apply some well-known algorithms. On the other hand, getting it past that moderate level of play does require knowledge, and the knowledge we have is not yet sufficient to do that. Hopefully my work on this topic will push us further down that road.
1. I’ve been writing OpenTafl with the intention that it be relatively easy to swap in different kinds of AI, both so that I can continue my research into tafl AI, and so that others can contribute. I suppose it may also find a place as a teaching tool, but that seems more unlikely. 2. Consider: at the start of the game, you can pick a common opening line, assume the other player will follow it to the end, and search from there, until the other player goes off-book. At the end of the game, you can search down to positions with a number of pieces—chess programs usually store a database of all endgames with five pieces, these days3—from which point you’re assured of perfect play. In either case, your effective search depth is your actual search depth plus the amount of information in the database. 3. Storage is the limiting factor. A five-move endgame database in the widely-accepted, heavily-compressed standard format is about 7 gb. There’s a chess program out there called Shredder which manages to pack it into 150 mb, two percent of the standard format, by removing any information besides whether the position is eventually won or eventually lost, and playing along those lines4. A six-piece database takes 1.2 tb in the standard form, which would be 24 gb in the Shredder format. The seven-piece tables come to between 100 tb to 150 tb, the range I’ve seen across a few sources, which would be take between two and three terabytes. Not really the sort of thing you’ll find in Chessmaster 2016. 4. It seems to me that without a native ordering, this method may take more moves to come to a winning position, but I suppose you can impose some order on them by adding ‘how long’ to the won or lost evaluation function, without taking up much more space. 5. I’m aware of only one place with any real detail, Tim Millar’s site. 6. Which isn’t a value judgement, mind. Go knowledge is nonformal, and in many ways seems largely aesthetic, but does eventually lead to wins, which makes it valuable, if hard to use from a game theory perspective. 7. Calculating the chess endgames with 7 pieces on an 8×8 board took a significant amount of time on a supercomputer in Moscow in 2012. On a 9×9 or 11×11 board, a tafl endgame with 7 taflmen is trivial—games usually end well before the amount of material on the board gets down to the amounts where enumeration of endgames is possible. 8. I’m reminded of my introduction of tafl to my residence hall my senior year of college. The initial feeling was that the besieging side had a massive advantage, but as we developed as players, we realized the advantage was much more on the king’s side. 9. Linnaeus, on his expedition to Lapland, observed the game being played and recorded the rules, thus saving tafl games for the ages.
IFVs are great for adding firepower to infantry units. And the standard arms race between gunmakers and armormakers has the added complication that the IFV has to carry some infantry to actually do its job. So, unlike tanks, it gets progressively harder to increase the gun caliber in an IFV if you actually want to carry an appreciable number of shells. One such answer can be found with a little inspiration from wildcat cartridge makers. We can take our regular autocannon round, neck the cartridge out so that it’s a straight-walled cylinder, replace the barrel with a bigger one, and get a more powerful round without sacrificing ammo capacity. The most potent such example was proposed in the 80s, and is known as the 50mm Supershot.
The base round is the 35x228mm autocannon round used in the Bushmaster III chain gun. Figuring that one couldn’t go much larger without serious complications (cf. the CV9040 with the 40mm Bofors and its pitiful ready capacity of 24 rounds), ammo designers in the 80s decided to try to make the 35mm round bigger. Necking it out gives you a diameter of 50mm, so that’s the caliber they went with. The resulting round is somewhat longer though to get the power right, since the rounds are semi-telescoped (i.e. the propellant doesn’t totally surround the round). Way cool. The 50mm Supershot gives the same propellant capacity as the 40mm Bofors round, which is a big plus. It’d be a hard-hitting KE round, and would have the capability to launch a significant amount of high explosive.
Development of the 50mm Supershot stopped with the end of the cold war. That hasn’t stopped us before though. What’s a bigger problem here is actually market forces. First, 35mm is not a very popular cannon round, which means there’s a much smaller pool of potential users to pool development costs and production runs amongst. 35mm is a big round, so those who favor the suppression fires type armaments are going to look elsewhere. Where the CV9030 holds 160 ready rounds of 30x173mm, the CV9035 holds only 70 ready rounds of 35mm. Even those nations who have gone with the 35mm (e.g. the Dutch) are likely to accept that as sufficient for the foreseeable future; the Dutch chose the 35mm as a hedge against uparmored BMP-3s which haven’t materialized, so why would they upgrade further?
The second problem is rival rounds, specifically the 40x255mm CTA. This round is fully telescoped, so the actual cartridge size is 65x220mm. That said, it’s remarkably compact and can be fit efficiently into ammo storage spaces. Because of the shortness of the round and the alternative feed system, you can fit more 40mm CTA rounds than 35mm rounds into a given volume. Plus, the 40mm CTA holds as much propellant as the 50mm Supershot, so you’re not giving up anything in the way of launching power. If we wanted firepower, the 40mm CTA is the way to go. When converting the Bradley to use the 40mm CTA, designers were able to fit 105 ready rounds, which is pretty impressive. If the designers worked with a purpose-designed turret, they could almost certainly fit somewhat more. Finally, the CTA round has already been developed and is entering production and service now, whereas the 50mm Supershot would need some time and money to complete development. On the other hand, we currently field 35mm guns, and more firepower on our IFVs is always a win.
Verdict: Referred to the Borgundy Army Ordnance Board for testing and development