This is the second article in a series on AI improvements to OpenTafl. Read the first part here.
Welcome back! In the first article in this series, I talked about what was, essentially, groundwork. I did gloss over two rather large bugs in the course of that article, so I’ll give them a deeper treatment before I dive into the three topics I have planned for today.
First: I failed altogether to mention a bug that cropped up while I was writing continuation search, and which, in actuality, prompted my creation of the AI consistency test. I have a bit of code around for extension searches (that is, searches that begin from a non-root node), whose purpose is to revalue all of the nodes above it. I was calling that method much too frequently, even during the main search, which pushed child values up the tree much too quickly, and yielded incorrect alpha-beta values. The bounds converged too quickly, and I ended up cutting off search far too early, before the search had verified that a certain move was safe in terms of opponent responses. I ended up designing a miniature tafl variant, 5×5 with a total of four pieces all limited to a speed of 1, to diagnose the issue. As a game, it’s unplayable, but the game tree to depth 3 takes about 30 or 40 lines, and it’s easy to read the tree and see what’s happening. That’s what I did, and that’s how I found my problem.
Second: the incomplete tree search bug, which I covered in a small amount of detail in a footnote. This one dates back to the very beginning of the OpenTafl AI, and is likely the cause of most of its weaknesses and obvious misplays since then. As I said in the text and the footnote, it stemmed from the assumption that a partial search of, for instance, depth 6 was better than a full search of depth 5. The true trickiness of this bug is that a partial search of depth 6 is, indeed, often as good as a full search of depth 5. All alpha-beta AIs prefer to search the best moves first, so if OpenTafl gets a little ways into the tree, a partial search at depth 6 is good enough to match the full search at depth 51.
The really awful part of this bug, the one which made it the most inconsistent, was that OpenTafl doesn’t always manage to assign a value to every state when it’s out of time. The states have a magic number value marking them as having no evaluation: -11541. This value ended up in the game tree, and it’s a very tempting move for the defender. Subtrees the defender had not finished exploring would be chosen over subtrees it had, leading to inconsistent and incorrect behavior. The solution, as I mentioned in the previous post, was, when starting search to a new depth, to save the search tree to the previous depth. If the new depth doesn’t finish, OpenTafl uses the complete tree from the previous depth.
Time use planning
That brings me quite naturally to my first new topic for today: time use planning. Getting time usage correct is tricky. Obviously, we want to search as deeply as possible in the main tree, but we also want to stop as soon as we know we can’t search to the next depth. Since we discard incomplete searches, any time spent on an unfinished search is wasted. Unfortunately, ‘can we search to the next depth?’ carries with it a good deal of uncertainty. OpenTafl now uses a few tricks to determine whether it should attempt a deeper search.
First, it better takes advantage of previous searches to a given depth. Concrete information is hard to come by for AIs, and ‘how long did it take me to do this last time?’ is pretty darned concrete2. Whenever a search is finished to a given depth, OpenTafl stores the time that search took in a table and sets the age of that data to zero. Whenever a search to a given depth fails, OpenTafl increments the age of the data for that depth. If the age exceeds a threshold, OpenTafl invalidates all the data at that depth and deeper.
When determining whether to embark on a search to the next depth, OpenTafl first checks the table. If it has data for the desired depth, it compares its time remaining to that figure. If there is no data, it synthesizes some. Obviously, we know how long it took to get to the current depth: we just finished searching to it. OpenTafl takes two factors into account: first, it’s hard to search to the next depth; and second, it’s harder to search to an odd depth than an even depth3. If going to an even depth, OpenTafl assumes it’ll be 10 times as hard as the previous depth; if going to an odd depth, OpenTafl assumes 20 times. These numbers are extremely provisional. Sometime down the line, I want to write some benchmarking code for various depths and various board sizes to generate some data to make those factors resemble reality more closely.
Second, OpenTafl reserves some time for extension searches. Horizon search oftentimes changes the end result of the evaluation, and so OpenTafl seems to play better when it has time to run. About 15% of the total think time for any given turn is set aside for extension searches.
Search heuristics #1: the history heuristic
On to the heuristics! I implemented two for this release. The first, the history heuristic, is one of my favorites. Much like dollar cost averaging4 in finance, the history heuristic says something which is, on reflection, blindingly obvious about alpha-beta searches, but something that nevertheless is not immediately apparent. It goes like this: moves which cause cutoffs, no matter where they appear in the tree, tend to be interesting, and worth exploring early.
Consider the game tree: that is, the tree of all possible games. It fans out in a giant pyramid shape, ever widening, until all of the possibilities peter out. Consider now the search tree: a narrow, sawtoothed path through the game tree, approaching terminal states until it finally alights upon one. The search tree always examines a narrow path through the tree, because the full game tree is so overwhelmingly large. Since the search tree examines a narrow path, similar positions are likely to come up in many different searches, and in similar positions, similar moves are likely to cause cutoffs. Therefore, whenever a move causes a cutoff, we ought to keep track of it, and if it’s a legal move in other positions, search it earlier.
That’s about all there is to it: the bookkeeping is a little more complicated, since we have to do something to be sure that cutoffs high up in the tree are given as much weight as cutoffs lower toward the leaves (OpenTafl increments the history table by remainingDepth squared), but that isn’t especially important to understand the idea.
There are two variations on the history heuristic I’ve considered or am considering. The first is the countermove history heuristic. The history heuristic in its simplest form is very memory-efficient: you only need  table entries; OpenTafl’s table entries are simple integers. Even for 19×19 tafl variants, the total size is less than half a megabyte. There exists a more useful expansion of the history heuristic sometimes called the countermove-history heuristic, which involves adding another two dimensions to the table: save cutoff counts per move and preceding move. This allows for a closer match to the situation in which the cutoffs were previously encountered, and increases the odds of a cutoff, but it turns out the inefficiency is too great in tafl games. Chess, with its more modest 8×8 board, can afford to bump the table entry requirement up to
table entries; OpenTafl’s table entries are simple integers. Even for 19×19 tafl variants, the total size is less than half a megabyte. There exists a more useful expansion of the history heuristic sometimes called the countermove-history heuristic, which involves adding another two dimensions to the table: save cutoff counts per move and preceding move. This allows for a closer match to the situation in which the cutoffs were previously encountered, and increases the odds of a cutoff, but it turns out the inefficiency is too great in tafl games. Chess, with its more modest 8×8 board, can afford to bump the table entry requirement up to 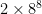 : it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case,
: it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case, 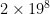 , or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.
, or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.
So I did some further reading on the subject, then came across another relation of the history heuristic: the relative history heuristic. It combines a plain history heuristic with something called the butterfly heuristic, which counts how many times a given position occurs in the tree. The relative history value of a state is its history heuristic value (the number of cutoffs it has caused) divided by its butterfly value (the number of times it has appeared in the tree). This makes the relative history heuristic a measure of the efficiency of a move: if a move appears ten times in the tree and causes ten cutoffs, it’s probably more interesting than a move that appears ten thousand times in the tree but only causes eleven cutoffs. I haven’t gotten around to it yet, but OpenTafl will probably include the relative history heuristic in a future AI release.
Search heuristics #2: the killer move heuristic
The killer move heuristic is the other heuristic I implemented for this release. The killer move heuristic is a special case of the history heuristic5, and turns out to be the single greatest improvement in OpenTafl’s strength I’ve implemented to date6.
What is it, then? Simply this: for each search, it tracks the two first moves which caused a cutoff at a given depth, along with the most recent move to do so, and plays those first whenever possible. See? Simple. It calls for very little explanation, and I’m already at nearly 2,000 words, so I’ll leave you with this. See you later this week for the thrilling conclusion.
- Advanced chess engines take advantage of this fact to search deeper: they do something called ‘late move reduction’, where the moves late in the move ordering are searched to a lesser depth, leaving more search time for the better moves (the ones earlier in move ordering). Move ordering in chess engines is usually good enough that that this works out.
- It isn’t always useful, though. Depending on what happens on the board and how well the move ordering happens to work, relative to the previous search, the next search may be very fast (if it’s something we expected) or very slow (if it completely blows up our plan).
- Even depths are usually small and odd depths are usually large, in terms of node counts relative to what you’d expect if the increase was linear. The mechanism of alpha-beta pruning causes this effect.
- Dollar cost averaging makes the incredibly obvious observation that, if you put money into an asset over time, fixed amounts at regular intervals, you end up buying more of the asset when the price is low than when the price is high. Because of numbers.
- Although the literature usually reverses this relationship: the history heuristic is normally referred to as a general case of the killer move heuristic, since the latter was used first.
- In two ways: first, the version with the killer move heuristic plays the best against other AIs; second, the version with the killer move heuristic deepens far, far faster. The killer move heuristic is, in fact, almost single-handedly responsible for that faster speed to a given depth, going by my benchmarks. In brandub, for instance, OpenTafl reaches depth 6 in 2.5 million nodes without the killer move heuristic, and 1.3 million nodes with it. Searching killer moves first yields the best result, and moving anything ahead of them in the search order is non-ideal.
Pingback: Opentaflvecken: final AI notes, plans for the future - The Soapbox