This is the third article in a series of posts on OpenTafl. You can read the first and second parts at the preceding links.
Welcome back to the third and final entry in Opentaflvecken, a one-week period in which I provide some minor respite to poor parvusimperator. We’ve hit the major AI improvements; now it’s time to cover a grab bag of miscellaneous topics left over. Onward!
Playing out repetitions
In OpenTafl’s versions of tafl rule sets, threefold repetitions are invariably handled: by default, it yields a draw; some variants define a threefold repetition as a win for the player moving into the third repetition of a board state1. Prior to the AI improvements release, the AI simply ignored repetitions, an obvious weakness: if you found a position where you could force OpenTafl to make repeated moves to defend, you could play the forcing move over and over, and OpenTafl would obligingly find a different way to answer it until it ran out and let you win. No longer! Now, OpenTafl is smart enough to play repetitions out to the end, using them to win if possible, or forcing a draw if necessary.
It turns out, as with everything in AI, this is not as simple as it sounds. The problem is the transposition table. It has no information on how many times a position has been repeated, and repetition rules introduce path dependency: the history of a state matters in its evaluation. Fortunately, this is a very simple path dependency to solve. OpenTafl now has a smallish hash table containing Zobrist hashes and repetition counts. Whenever a position appears, either in the AI search or in the regular play of the game, the repetition count is incremented. Whenever the AI finishes searching a position, it is removed from the table. In this way, at any given state, the AI always knows how many times a position has occurred. If the position has occurred more than once in the past, the AI skips the transposition table lookup and searches the position instead. This seems like it might cause a search slowdown—repetitions can no longer be probed—but in practice, it’s turned out to have almost no effect.
Move ordering improvements
I discussed move ordering a little bit in the second article, but I want to go into a little more depth. Move ordering is the beating heart of any alpha-beta search engine. The better the move ordering, the better the pruning works; the better the pruning works, the deeper the AI can search; the deeper the AI can search, the better it plays. Early on in OpenTafl’s development, I threw together a very simple move ordering function: it searched captures first and everything else later. Later on, after the transposition table went in, I added a bit to try transposition table hits in between captures and the remaining moves. The move ordering used Java’s sort method, which, though efficient, is more ordering than is necessary.
Late in the AI improvements branch, when I added the killer move table and the history table, I decided to fix that. Move ordering now does as little work as possible: it makes one pass through the list of moves, putting them into buckets according to their move type. It sorts the transposition table hits and history table hits, then searches the killer moves, the history table hits, the top half of the transposition table hits, the captures, the bottom half of the transposition table hits, and finally, any moves which remain. Though there are two sorts here instead one, since they’re much smaller on average, they’re faster overall.
Puzzles
Okay, this one isn’t exactly an AI feature, but you’ll note that the title doesn’t limit me to AI future plans only. It also turns out that this isn’t much of a future plan. Puzzles are already done on the unstable branch, so I’ll use this section to tell you about the three kinds of puzzles.
The first is the least heavily-annotated sort, the one you might find on the hypothetical chess page of a newspaper: simply a rules string, a position string, and a description along the lines of ‘white to win in 4’. OpenTafl supports these with the new load notation feature: paste an OpenTafl rules string into a dialog box, and OpenTafl will load it. (There’s also a new in-game/in-replay command which can be used to copy the current position to the clipboard, ctrl+c and ctrl+v being nontrivial for the moment.)
The other two are closely related. They start with a standard OpenTafl replay, then use some extra tags to declare that the replay file defines a puzzle, and tell OpenTafl where in the replay file the puzzle starts. The puzzle author uses OpenTafl’s replay editing features to create variations and annotations for all of the branches of play he finds interesting, then distributes the file. When loading the file, OpenTafl hides the history until the player explores it. The two closely-related kinds I mentioned are loose puzzles and strict puzzles, the only difference being that loose puzzles allow the player to explore branches the puzzle author didn’t include, while strict puzzles do not.
OpenTafl has all the tools you need to author puzzles, although, at present, you will have to do your own position records. (Sometime down the line, I’d like to add a position editor/analysis mode, but today is not that day.) The README will have more details.
You can expect two or three puzzles to ship with the OpenTafl v0.4.4.0b release, along with all puzzle-related features.
Future evaluation function plans
I mentioned before that there are some weaknesses in the current evaluation function, and that some changes will be required. I’m becoming more convinced that this is untrue, and that what I really ought to do is an evaluation function which is easier for humans to understand. The current evaluation function just places an abstract value on positions; the one I’d like to do uses the value of a taflman as an easy currency. In doing so, I can ask myself, “Would I sacrifice a taflman to do X?” Having that as a check on my logic would be nice, and would prevent me from making dumb logic errors like the one in the current evaluation function, where the attacker pushes pieces up against the king much too eagerly.
This may also require more separation in the evaluation function between different board sizes; sacrificing a taflman in a 7×7 game is a bigger decision than sacrificing one in an 11×11 game. I may also have some changing weights between the opening and the endgame, although, as yet, I don’t have a great definition for the dividing line between opening and endgame.
Anyway, that’s all theoretical, and undoubtedly I’ll be writing about it when I get to it, as part of the v0.4.5.x series of releases. In the meantime, though, I have plenty to do to get v0.4.4.0b done. I’ll be testing this one pretty hard, since it’s going to be the next stable release, which involves a lot of hands-on work. The automated tests are great, but can’t be counted on to catch UI and UX issues.
Thanks for joining me for Opentaflvecken! Remember, the AI tournament begins in about three and a half months, so you still have plenty of time to hammer out an AI if you’d like to take part. Hit the link in the header for details.
- This isn’t exactly intuitive, but the person moving into a state for the third time is the person whose hand is forced. (Play it out for yourself if you don’t believe me.) Although it’s traditional to declare a threefold repetition a draw, I think it works better in tafl if the player making the forcing move is forced to make a different move or lose.

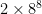 : it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case,
: it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case, 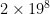 , or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.
, or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.