This month we bring you a very special edition of the Crossbox Podcast! Listen to us chat about game design and the Battle of Midway.
(Download)
This month we bring you a very special edition of the Crossbox Podcast! Listen to us chat about game design and the Battle of Midway.
Not very hard, I admit: I’ll grant you that the AR-15 is an excellent example of a weapon design which is easy to work on, easy to assemble, and easy to maintain. As far as building your own goes, the AR-15 is a lot like democracy: the worst system, except for all the other ones we’ve tried.
That being said, though, no other rifle has the same reputation as the AR-15, whose marketing says that any enterprising citizen with some tools in the basement can knock one together from your various parts kits. This is technically correct, and while I’m on the record saying that technically correct is the best kind of correct, I have to throw the flag here, for two separate reasons.
First: the AR-15 in its original design does require specialist tools, to attach a pinned gas block. Fortunately for modern end users, set screw and clamp-on gas blocks are much more popular, because they, y’know, work just as well. If you build to the original spec, you need a drill press, which brings us to…
Second: the fairer comparison is an 80% AR lower against an 80% AK blank. You’ll need a drill press for the AR lower as well as the AK blank; there’s just less of a market for AK building because it doesn’t have that Lego feel.
Beyond that, the AR has a ton of annoying fiddly bits which, while still better than, say, rivets, are still a pain. Consider the barrel nut. Rather than having a single purpose and a single torque specification, it has two purposes and a massive torque range: it holds the barrel to the receiver, and it supports the gas tube through its notched flange while being locked in place by same. This is an example of too-clever-by-half thinking. The barrel nut ought to just be a regular nut, and when designing a regular nut, it’s best to rely on torque over some external device designed to inhibit the rotation of the nut. If the gas tube needs support, design a separate part for that.
Consider also the roll pin. Sure, it does its job, but at what cost? In most cases where I may want to remove a part, I prefer set screws or mechanically-retained pins. (Remember, I have c-spring retained trigger and hammer pins on my lower receiver.) I will grant that the roll pin is fine in some places. For instance, I don’t intend to ever replace the trigger guard on my lower receiver, so roll pins are fine! Similarly, I don’t plan on unpinning the gas tube from the gas block; if I have to replace one, or if I want to change one, I’ll replace them as a unit. Same deal: roll pins cool.
Parvusimperator asked me to gripe about the dust cover, but I (intelligently) bought an upper receiver which already has the dust cover installed.
The worst part is that most of these failings need not be failings! It’s dead simple to make an AR-15-compatible receiver. Upper receivers especially already exist to meet a myriad of needs. Why not improved end-user serviceability? Lowers are a harder pill to swallow, since ‘needs special parts’ is a terrible thing to see on the side of one. Then again, ambidextrous lower receivers are a thing, and most end users are only going to bother changing furniture, triggers, and maybe buffers, none of which are big offenders in the special-tools market. The same reasoning holds here. We already have specialist AR-15 lowers for the ambidextrously-interested. Why not for the bolt-catch-replacingly-interested?
In a previous post, I alluded to the canonical article on AR 7.62×39. That is this article, an excellent resource by a guy who goes by Major Pandemic1. It identifies two issues with AR functioning in 7.62×39 rifles: cycling, which I will use to mean exclusively the movement of the action, and feeding, which I will use to mean the process by which ammunition is stripped from the top of the magazine and pushed forward into the chamber. These two issues are, at their base, related, and Major Pandemic hits upon the solutions pretty quickly, along with one which I believe to be superfluous. This is because he hit them in the wrong order.
It’s impossible to claim an AR-pattern rifle is unreliable without first making sure the gas system is functioning as designed. Thanks to parvusimperator’s recent book acquisitions on and general encyclopedic knowledge of the history of the scary black rifle, I have a few instances to cite. First on the list are the M16 and M16A1, where a change in powder from stick-type to ball-type yielded a change in pressure curve. The result: unreliable functioning2. Rounding out the list are your various carbines, from the CAR-15 in the 1960s and 1970s to the M4 carbine through to the super-short Mark 18/Close Quarters Battle Receiver, all of which fall prey to another issue: changing the barrel length without changing the gas system. When you shorten (or lengthen) a barrel, you decrease (or increase) the dwell time. That figure, the measure of how long a bullet stays in the barrel (and barrel pressures remain high), combines with the pressure curve to determine where the gas port should be placed, and how large the gas port ought to be.
Fortunately for 5.56 NATO shooters, the hard work has already been done, and barrel manufacturers have the sizes and locations pretty much figured out. Unfortunately for we 7.62 Russian Short shooters, the same body of work is not yet done, and shooting a different cartridge with a vastly different pressure profile is the very definition of messing around with the gas system. When doing your function tests, be prepared! If you run into cycling issues, try a lightweight buffer and/or a lightweight spring. (I believe the received wisdom is to try them in that order. Parvusimperator will correct me, if not.†) If that doesn’t suffice, you may have to increase the size of your gas port. With a drill, I mean, and a bit. Don’t increase the size too fast: my 7.62 AR functions perfectly with a factory gas tube size of about 1/12″. If you get to larger than 1/8″, you’ve almost certainly done something else wrong. A bluing pen (if you’re using a blued or nitrided barrel) should give you some finish around the gas port.
Next, and obviously, get dedicated magazines. The 7.62×39 cartridge is obscenely tapered, and only magazines specifically designed for it will push your cartridges up in front of the bolt carrier proper-like. This isn’t .300 Blackout; it’s not shaped anything like a 5.56 round, and any magazine not designed to feed 7.62×39, in a word, won’t. Midway’s AR-Stoner brand works well, and they won’t break the bank.
That brings us to feeding issues. By this point, you shouldn’t have any. If you clicked through to Major Pandemic’s article, you’ll see that he decided to dremel out the divider between the feed ramps. Granted, Bushmaster’s successful, functional 7.62×39 AR took the same tack, but my suspicion is that they made the same mistake other manufacturers, plus innumerable individual builders, made: an undergassed or overbuffered gun leaving magazines insufficient time to fully feed the next cartridge before the bolt carrier returns.
If and only if you simply can’t get your rifle to function correctly, you may consider a few courses of action before breaking out the dremel. Different magazines may help. It’s a bit of a shame that you may have to match a specific brand of magazine to your rifle, but if you were expecting rock-solid reliability with any equipment you care to find, you should have bought an AK. You might also try shooting it more. There’s a break-in period to any gun, and springs and lubrication may not take at first. If you do resort to dremeling and you have a barrel with a finish, don’t forget the wee touch-up pen to get your corrosion resistance back.
I think I’ll close with one final note on barrel selection. Faxon Firearms, who I’ve mentioned before, seem to make an excellent product with a gas port able to run just about any example of our favorite Russian intermediate cartridge without issue. I recommend their product. If you ignore that recommendation, I would at least suggest you look for a nitrided/Melonited barrel. Nothing else really makes sense for 7.62×39: presumably, you’re going to want to shoot cheap steel-cased, bimetal-jacket ammo, and a harder barrel helps to offset the additional wear you get from that choice. Combine that with the much lower velocities you have to work with compared to 5.56, and you may be surprised at the barrel life you end up with.
Then again, you may not. As you may have noticed, we don’t have sponsors around here, so I’m engaging in the most rampant of rampant speculation, not being able to afford 1) a second barrel to beat up and 2) the 20,000-40,000 rounds of ammunition it would likely take to really blow the first item out. As always, we’re curious about your experiences with 7.62×39 ARs, dear reader, so leave a comment if you have any.
1. I’m hardly one to talk about strange monikers, though.
2. I found some rather morbid documented accounts of US soldiers found dead next to malfunctioned, torn-down M16s, suggesting the men were killed while trying to fix their rifles.
† I would very strongly recommend messing with buffers, buffer weights, or even a reduced mass bolt carrier before touching the buffer spring. There are plenty of options out there to reduce the mass of the operating components if you want to go that route. Clipping spring coils is a good way to get plenty of malfunctions. -parvusimperator
That’s right. It finally happened.
Of course, it’s me, so I built it from a lower parts kit (some years ago) and random upper parts (a few days back), not simply by pinning a prebuilt lower and upper together.
Oh, and it’s in 7.62×39. That’s right: an AR-15 in 7.62×39. A 7.62×39 AR-151.
First thing’s first. Why ARK? Well, I have two existing 7.62×39 rifles. One is the BRK, the Bullpapniy Russkiy Karabin. Another is Kat, which is my competition Russkiy Karabin, or CRK. There’s an obvious theme developing here, so ARK it had to be. In traditional Fishbreath rifle naming style, the acronym has two meanings. The first, most obvious one is that the rifle is an AK caliber in an AR pattern: AR-K. The second is the also-traditional Russian name, the Amerikansko-Russkiy Karabin.
Why build an AR-15 in 7.62×39, you ask? I have a few reasons. First: it’s a deeply underrated caliber. It can do everything .300 Blackout can do, although I grant it’s harder to find subsonic 7.62×39 than .300 Blackout. In ballistic terms, the two cartridges are so nearly identical that the drop-compensating reticle in my chosen optic works for both with the same zero. The difference between the two comes down not to innate capabilities, but to modern development effort2.
Second: the AR platform is admittedly pretty neat. I can hardly deny that the ergonomics are good, and the Lego-for-adults aspect is deeply appealing to me, an adult who rather wishes he had more Legos.
Third: I can’t abide by being so normal as to build an AR in 5.56. Parvusimperator often accuses me of being a gun hipster… and I absolutely agree. An AR-15 in 5.56 does very little to interest me: hipsterish though this sentence may be, it’s played out. 7.62×39 is much more oddball, and therefore more interesting as an exercise.
Fourth: ammo is super-cheap, even if I have to pop by a local gun store. Much ink has been spilled on this front, so I won’t spend too much time on it. Suffice it to say that I don’t even mind having to occasionally pay friendly local gun shop prices for 7.62×39.
To be honest, though, it’s mostly the hipster factor. 7.62×39 AR is an odd combo, I like odd combos, and most of all, I like building things. Let’s get into the nitty gritty on parts.
Lower receiver
Surplus Ammo in Washington State, which is mainly a surplus ammo outfit, also makes decent forged lower receivers. It’s a lower. How much is there to say?
Lower parts/furniture
I got the standard Palmetto State parts kit, minus grip and stock. All the mechanical/internal gubbins are the same, with the exception of the trigger and hammer pins. I went with versions retained by wee c-springs for those, since I’d been hearing horror stories about the pins coming out under use at the time. It seems unlikely, pressing on the pins with my thumbs now, that they might, but better safe than sorry.
For the grip and stock, I went with the sadly-discontinued ATI Strikeforce set. The grip is heftier than most AR-15 grips, swelling to actually fill an average-sized hand, and nicely padded. The stock has an adjustable cheek riser which I’m not currently using, and is also padded. I purchased this set when I was planning to make this lower a 6.5 Grendel rifle, so that explains the slightly more marksman-oriented setup.
Upper receiver
Again, I went to Surplus Ammo, who had a billet upper in stock, charging handle included, for $75 delivered. I have a hard time arguing with that. It has a dust cover and a forward assist, as the Army intended. No side-charging or anything like that. It’s a $75 receiver. You can’t expect much beyond the standard for that money.
Barrel
Faxon Firearms makes a 7.62×39 barrel with a 1-8″ twist. Unfortunately, it’s built to the surprisingly odd government profile, but crucially, it has a much larger gas port than your average 5.56 barrel. Since 7.62×39 is a lower-pressure cartridge by a significant margin, the extra gas port diameter is all but a requirement for adequate functioning.
The 1-8″ twist is also nice: a faster twist can better stabilize a heavy cartridge, and if I eventually load subsonic ammo for this rifle, that’s a handy trick.
Bolt carrier group
LJ’s AR Parts, who I had not heard of until I built this rifle, make a nitride BCG with an extended firing pin for better primer strikes on the harder primers of the standard cheapo steel-case ammo often fired through 7.62×39 rifles. That’s the one I’m using.
Gas block
I got one of the low-profile ones wot attaches by set screw. I prefer set screws to pins in basically every case.
Handguard
Parvusimperator had a spare Troy Industries 9″ jobber lying around. It’s a nice lightweight handguard, ventilated so it doesn’t get hot easily. It also avoids the quadrail problem of heavy rails you don’t need by having a single top rail with attachable sections for other accessories.
Muzzle device
I went with the Strike Industries King Comp, which is well-reviewed and seems effective enough. In my estimation, it works better than the AK-74-style brake. Happily, it’s not quite as bad in terms of side concussion as Parvusimperator’s favored brakes, although it does considerably increase the noise. Factoring in my ear protection, I had a hard time differentiating the report from Parvusimperator’s Garand and the ARK.
Magazines
Ordinarily, these wouldn’t merit mention, but this is a 7.62×39 AR-15 we’re talking about, and standard magazines need not apply. I found Midway’s house brand, AR Stoner, works fine.
Sights
Finally, the bit I alluded to at the very beginning. I chose a fancier optic than is my usual wont: the Primary Arms 1-6x ACSS scope for 7.62×39/300 Blackout. I have to say, I’m sold on the concept: an illuminated variable-power optic with 1x or near-1x magnification on the low end, for use as a red dot-style sight close up, and a bullet drop compensation reticle for longer-range work. This one is a particularly nice example. Parvusimperator, that noted glass snob, said the glass is “not bad”. The reticle is perfect for my purposes: a large illuminated chevron, to be zeroed at 50 yards, plus drop markings for 300-600 yards, the latter being just about the maximum effective range for 7.62×39. Rangefinding markings for each range are built into the reticle ACOG-style, where the crosshatch on the vertical line corresponding to a given range matches the width of an adult male’s shoulders at the same range. There’s also a rangefinder marking off to the side for standing height.
Other handy markings include dots for a 5mph crosswind at each range, and dots for leading a running target (at 8.6 mph, the generally-accepted speed for a man running with a rifle). The latter isn’t especially useful to me, since I don’t really hunt for anything, much less the most dangerous game. The former dots are nice to have, though; crosswind shooting comes up a lot, although I don’t expect it to do so too much with this rifle.
Final notes
There’s a canonical article on AR-15/7.62×39 reliability I want to address fully in a later post, but I do want to touch on reliability concerns and my results here. I went into this project with some trepidation on the reliable-functioning front, but emerged from Saturday’s range test with no remaining concerns: 40 rounds of slow fire while I was zeroing my scope and verifying that zero yielded no problems. Nor did 60 rounds of rapid fire, including some fast double taps, from magazines loaded to a full 30 rounds. 7.62×39 AR owners commonly cite two related pain points: cycling and feeding. For 7.62×39, you want a biggish gas port for the barrel length: at 0.087″, the port on the Faxon barrel in the ARK would yield a tremendously overgassed rifle for 5.56, but seems just about right for the ARK.
I’ve hit my about-1400-words target pretty handily with this first article. Stay tuned for the next one, in which I rag on the AR as a platform!
This sale has now ended.
Over at Many Words Press, we have a sale running on my e-book, [url=http://manywords.press/archives/2918/sail-off-war-first-royalties-sale]We Sail Off To War[/url]. Get it for the low, low price of 99 cents, this week only!
In this episode, Jay rambles for a full half hour on a gun topic (a Crossbox first!), we trash a three-gun group whose rules specify what color your magazines are (and are not) allowed to be, we make a connection between Bond and Longstreet, and we decide that the French aren’t so bad after all.
Further reading
Jay’s Goldeneye Source review in one line (approximately): wow, how old-school. I don’t remember it taking this many bullets to kill someone. Oh, right. I always used the P90. That’s why.
Goldeneye Source
Civil War II
Your Korean tank…
… and IFV
The FREMM
And the Gripen
This is the third article in a series of posts on OpenTafl. You can read the first and second parts at the preceding links.
Welcome back to the third and final entry in Opentaflvecken, a one-week period in which I provide some minor respite to poor parvusimperator. We’ve hit the major AI improvements; now it’s time to cover a grab bag of miscellaneous topics left over. Onward!
Playing out repetitions
In OpenTafl’s versions of tafl rule sets, threefold repetitions are invariably handled: by default, it yields a draw; some variants define a threefold repetition as a win for the player moving into the third repetition of a board state1. Prior to the AI improvements release, the AI simply ignored repetitions, an obvious weakness: if you found a position where you could force OpenTafl to make repeated moves to defend, you could play the forcing move over and over, and OpenTafl would obligingly find a different way to answer it until it ran out and let you win. No longer! Now, OpenTafl is smart enough to play repetitions out to the end, using them to win if possible, or forcing a draw if necessary.
It turns out, as with everything in AI, this is not as simple as it sounds. The problem is the transposition table. It has no information on how many times a position has been repeated, and repetition rules introduce path dependency: the history of a state matters in its evaluation. Fortunately, this is a very simple path dependency to solve. OpenTafl now has a smallish hash table containing Zobrist hashes and repetition counts. Whenever a position appears, either in the AI search or in the regular play of the game, the repetition count is incremented. Whenever the AI finishes searching a position, it is removed from the table. In this way, at any given state, the AI always knows how many times a position has occurred. If the position has occurred more than once in the past, the AI skips the transposition table lookup and searches the position instead. This seems like it might cause a search slowdown—repetitions can no longer be probed—but in practice, it’s turned out to have almost no effect.
Move ordering improvements
I discussed move ordering a little bit in the second article, but I want to go into a little more depth. Move ordering is the beating heart of any alpha-beta search engine. The better the move ordering, the better the pruning works; the better the pruning works, the deeper the AI can search; the deeper the AI can search, the better it plays. Early on in OpenTafl’s development, I threw together a very simple move ordering function: it searched captures first and everything else later. Later on, after the transposition table went in, I added a bit to try transposition table hits in between captures and the remaining moves. The move ordering used Java’s sort method, which, though efficient, is more ordering than is necessary.
Late in the AI improvements branch, when I added the killer move table and the history table, I decided to fix that. Move ordering now does as little work as possible: it makes one pass through the list of moves, putting them into buckets according to their move type. It sorts the transposition table hits and history table hits, then searches the killer moves, the history table hits, the top half of the transposition table hits, the captures, the bottom half of the transposition table hits, and finally, any moves which remain. Though there are two sorts here instead one, since they’re much smaller on average, they’re faster overall.
Puzzles
Okay, this one isn’t exactly an AI feature, but you’ll note that the title doesn’t limit me to AI future plans only. It also turns out that this isn’t much of a future plan. Puzzles are already done on the unstable branch, so I’ll use this section to tell you about the three kinds of puzzles.
The first is the least heavily-annotated sort, the one you might find on the hypothetical chess page of a newspaper: simply a rules string, a position string, and a description along the lines of ‘white to win in 4’. OpenTafl supports these with the new load notation feature: paste an OpenTafl rules string into a dialog box, and OpenTafl will load it. (There’s also a new in-game/in-replay command which can be used to copy the current position to the clipboard, ctrl+c and ctrl+v being nontrivial for the moment.)
The other two are closely related. They start with a standard OpenTafl replay, then use some extra tags to declare that the replay file defines a puzzle, and tell OpenTafl where in the replay file the puzzle starts. The puzzle author uses OpenTafl’s replay editing features to create variations and annotations for all of the branches of play he finds interesting, then distributes the file. When loading the file, OpenTafl hides the history until the player explores it. The two closely-related kinds I mentioned are loose puzzles and strict puzzles, the only difference being that loose puzzles allow the player to explore branches the puzzle author didn’t include, while strict puzzles do not.
OpenTafl has all the tools you need to author puzzles, although, at present, you will have to do your own position records. (Sometime down the line, I’d like to add a position editor/analysis mode, but today is not that day.) The README will have more details.
You can expect two or three puzzles to ship with the OpenTafl v0.4.4.0b release, along with all puzzle-related features.
Future evaluation function plans
I mentioned before that there are some weaknesses in the current evaluation function, and that some changes will be required. I’m becoming more convinced that this is untrue, and that what I really ought to do is an evaluation function which is easier for humans to understand. The current evaluation function just places an abstract value on positions; the one I’d like to do uses the value of a taflman as an easy currency. In doing so, I can ask myself, “Would I sacrifice a taflman to do X?” Having that as a check on my logic would be nice, and would prevent me from making dumb logic errors like the one in the current evaluation function, where the attacker pushes pieces up against the king much too eagerly.
This may also require more separation in the evaluation function between different board sizes; sacrificing a taflman in a 7×7 game is a bigger decision than sacrificing one in an 11×11 game. I may also have some changing weights between the opening and the endgame, although, as yet, I don’t have a great definition for the dividing line between opening and endgame.
Anyway, that’s all theoretical, and undoubtedly I’ll be writing about it when I get to it, as part of the v0.4.5.x series of releases. In the meantime, though, I have plenty to do to get v0.4.4.0b done. I’ll be testing this one pretty hard, since it’s going to be the next stable release, which involves a lot of hands-on work. The automated tests are great, but can’t be counted on to catch UI and UX issues.
Thanks for joining me for Opentaflvecken! Remember, the AI tournament begins in about three and a half months, so you still have plenty of time to hammer out an AI if you’d like to take part. Hit the link in the header for details.
I am not a rocket scientist, but I do like to think about engineering problems.
Here are the facts as we know them:
Now, for a rocket to fail during fueling, before engine firing—as the most recent Falcon failed—is very unusual. To my engineer’s mind, it suggests a materials problem in the LOX or liquid helium tanks, something failing in an unexpected way when deep-chilled. Crucially, the Falcon 9’s LOX tank experiences the coldest temperature (for a LOX tank) in the history of rocketry. Take that in combination with the failure on the CRS-7 mission: after their investigation, SpaceX switched to a new strut, which means new failure modes.
Mark my words (and feed them to me along with a heaping helping of crow, when I turn out to be wrong): this is another strut issue, be it faulty or just unsuited for the deep-cryo fuel in some other way.
This is the second article in a series on AI improvements to OpenTafl. Read the first part here.
Welcome back! In the first article in this series, I talked about what was, essentially, groundwork. I did gloss over two rather large bugs in the course of that article, so I’ll give them a deeper treatment before I dive into the three topics I have planned for today.
First: I failed altogether to mention a bug that cropped up while I was writing continuation search, and which, in actuality, prompted my creation of the AI consistency test. I have a bit of code around for extension searches (that is, searches that begin from a non-root node), whose purpose is to revalue all of the nodes above it. I was calling that method much too frequently, even during the main search, which pushed child values up the tree much too quickly, and yielded incorrect alpha-beta values. The bounds converged too quickly, and I ended up cutting off search far too early, before the search had verified that a certain move was safe in terms of opponent responses. I ended up designing a miniature tafl variant, 5×5 with a total of four pieces all limited to a speed of 1, to diagnose the issue. As a game, it’s unplayable, but the game tree to depth 3 takes about 30 or 40 lines, and it’s easy to read the tree and see what’s happening. That’s what I did, and that’s how I found my problem.
Second: the incomplete tree search bug, which I covered in a small amount of detail in a footnote. This one dates back to the very beginning of the OpenTafl AI, and is likely the cause of most of its weaknesses and obvious misplays since then. As I said in the text and the footnote, it stemmed from the assumption that a partial search of, for instance, depth 6 was better than a full search of depth 5. The true trickiness of this bug is that a partial search of depth 6 is, indeed, often as good as a full search of depth 5. All alpha-beta AIs prefer to search the best moves first, so if OpenTafl gets a little ways into the tree, a partial search at depth 6 is good enough to match the full search at depth 51.
The really awful part of this bug, the one which made it the most inconsistent, was that OpenTafl doesn’t always manage to assign a value to every state when it’s out of time. The states have a magic number value marking them as having no evaluation: -11541. This value ended up in the game tree, and it’s a very tempting move for the defender. Subtrees the defender had not finished exploring would be chosen over subtrees it had, leading to inconsistent and incorrect behavior. The solution, as I mentioned in the previous post, was, when starting search to a new depth, to save the search tree to the previous depth. If the new depth doesn’t finish, OpenTafl uses the complete tree from the previous depth.
Time use planning
That brings me quite naturally to my first new topic for today: time use planning. Getting time usage correct is tricky. Obviously, we want to search as deeply as possible in the main tree, but we also want to stop as soon as we know we can’t search to the next depth. Since we discard incomplete searches, any time spent on an unfinished search is wasted. Unfortunately, ‘can we search to the next depth?’ carries with it a good deal of uncertainty. OpenTafl now uses a few tricks to determine whether it should attempt a deeper search.
First, it better takes advantage of previous searches to a given depth. Concrete information is hard to come by for AIs, and ‘how long did it take me to do this last time?’ is pretty darned concrete2. Whenever a search is finished to a given depth, OpenTafl stores the time that search took in a table and sets the age of that data to zero. Whenever a search to a given depth fails, OpenTafl increments the age of the data for that depth. If the age exceeds a threshold, OpenTafl invalidates all the data at that depth and deeper.
When determining whether to embark on a search to the next depth, OpenTafl first checks the table. If it has data for the desired depth, it compares its time remaining to that figure. If there is no data, it synthesizes some. Obviously, we know how long it took to get to the current depth: we just finished searching to it. OpenTafl takes two factors into account: first, it’s hard to search to the next depth; and second, it’s harder to search to an odd depth than an even depth3. If going to an even depth, OpenTafl assumes it’ll be 10 times as hard as the previous depth; if going to an odd depth, OpenTafl assumes 20 times. These numbers are extremely provisional. Sometime down the line, I want to write some benchmarking code for various depths and various board sizes to generate some data to make those factors resemble reality more closely.
Second, OpenTafl reserves some time for extension searches. Horizon search oftentimes changes the end result of the evaluation, and so OpenTafl seems to play better when it has time to run. About 15% of the total think time for any given turn is set aside for extension searches.
Search heuristics #1: the history heuristic
On to the heuristics! I implemented two for this release. The first, the history heuristic, is one of my favorites. Much like dollar cost averaging4 in finance, the history heuristic says something which is, on reflection, blindingly obvious about alpha-beta searches, but something that nevertheless is not immediately apparent. It goes like this: moves which cause cutoffs, no matter where they appear in the tree, tend to be interesting, and worth exploring early.
Consider the game tree: that is, the tree of all possible games. It fans out in a giant pyramid shape, ever widening, until all of the possibilities peter out. Consider now the search tree: a narrow, sawtoothed path through the game tree, approaching terminal states until it finally alights upon one. The search tree always examines a narrow path through the tree, because the full game tree is so overwhelmingly large. Since the search tree examines a narrow path, similar positions are likely to come up in many different searches, and in similar positions, similar moves are likely to cause cutoffs. Therefore, whenever a move causes a cutoff, we ought to keep track of it, and if it’s a legal move in other positions, search it earlier.
That’s about all there is to it: the bookkeeping is a little more complicated, since we have to do something to be sure that cutoffs high up in the tree are given as much weight as cutoffs lower toward the leaves (OpenTafl increments the history table by remainingDepth squared), but that isn’t especially important to understand the idea.
There are two variations on the history heuristic I’ve considered or am considering. The first is the countermove history heuristic. The history heuristic in its simplest form is very memory-efficient: you only need  table entries; OpenTafl’s table entries are simple integers. Even for 19×19 tafl variants, the total size is less than half a megabyte. There exists a more useful expansion of the history heuristic sometimes called the countermove-history heuristic, which involves adding another two dimensions to the table: save cutoff counts per move and preceding move. This allows for a closer match to the situation in which the cutoffs were previously encountered, and increases the odds of a cutoff, but it turns out the inefficiency is too great in tafl games. Chess, with its more modest 8×8 board, can afford to bump the table entry requirement up to
table entries; OpenTafl’s table entries are simple integers. Even for 19×19 tafl variants, the total size is less than half a megabyte. There exists a more useful expansion of the history heuristic sometimes called the countermove-history heuristic, which involves adding another two dimensions to the table: save cutoff counts per move and preceding move. This allows for a closer match to the situation in which the cutoffs were previously encountered, and increases the odds of a cutoff, but it turns out the inefficiency is too great in tafl games. Chess, with its more modest 8×8 board, can afford to bump the table entry requirement up to 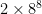 : it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case,
: it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case, 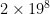 , or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.
, or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.
So I did some further reading on the subject, then came across another relation of the history heuristic: the relative history heuristic. It combines a plain history heuristic with something called the butterfly heuristic, which counts how many times a given position occurs in the tree. The relative history value of a state is its history heuristic value (the number of cutoffs it has caused) divided by its butterfly value (the number of times it has appeared in the tree). This makes the relative history heuristic a measure of the efficiency of a move: if a move appears ten times in the tree and causes ten cutoffs, it’s probably more interesting than a move that appears ten thousand times in the tree but only causes eleven cutoffs. I haven’t gotten around to it yet, but OpenTafl will probably include the relative history heuristic in a future AI release.
Search heuristics #2: the killer move heuristic
The killer move heuristic is the other heuristic I implemented for this release. The killer move heuristic is a special case of the history heuristic5, and turns out to be the single greatest improvement in OpenTafl’s strength I’ve implemented to date6.
What is it, then? Simply this: for each search, it tracks the two first moves which caused a cutoff at a given depth, along with the most recent move to do so, and plays those first whenever possible. See? Simple. It calls for very little explanation, and I’m already at nearly 2,000 words, so I’ll leave you with this. See you later this week for the thrilling conclusion.
If you’re a regular reader over at Many Words Main, you’ll undoubtedly have thought that I’m some kind of bum, missing another update so soon. Not so! I’ve been very busy on other projects; very busy indeed. In a series of articles this week, I’ll be going through improvements I’ve made to OpenTafl’s AI. I’ll be releasing a stable version out of v0.4.3.x soon, which will feature the structural improvements I’ve made so far; next up will be puzzles in v0.4.4.x, then AI state evaluation improvements in v0.4.5.x.
So, what have I been up to? Well, let me open up my source control log, and I’ll tell you. Note I’m not reporting my progress in chronological order here: I present to you a natural-seeming order of features which bears little resemblance to reality, but which does make for a neater story.
Groundwork
Before embarking on a project as fuzzy as AI improvements, I needed tools to tell me whether my changes were making a positive effect. I started with a simple one: a command which dumps the AI’s evaluation of a particular state. This lets me verify that the evaluation is correct, and it turns out (to nobody’s great surprise) that it is not. When playing rules with weak kings, the AI places far too much weight on having a piece next to the king. When playing rules with kings which aren’t strong (tablut, for instance), the AI still mistakenly assumes that placing one piece next to the king is the same as putting the king in check. An improvement to make for phase 2!
The next thing on the docket was a test. As I wrote about what feels like a lifetime ago, OpenTafl is a traditional game-playing artificial intelligence. It uses a tree search algorithm called minimax with alpha-beta pruning, which is an extension of the pure minimax algorithm. The latter simply plays out every possible game to a certain depth, then evaluates the board position at the end of each possibility, then picks the best one to play toward, bearing in mind that the other player will make moves which are not optimal from its perspective1. Alpha-beta pruning extends minimax by taking advantage of the way we search the tree: we go depth first, exploring leaf nodes from ‘left’ to ‘right’2. As we move to the right, we discover nodes that impose bounds on the solution. Nodes which fall outside those bounds need not be considered. (The other article has an example.)
Anyway, the upshot of the preceding paragraph is that, for any given search, minimax and minimax with alpha-beta pruning should return the same move3. Previously, I had no way of verifying that this was so. Fortunately, it turned out that it was, and out of the whole endeavor I gained an excellent AI consistency test. It runs several searches, starting with all of OpenTafl’s AI features turned off to do a pure minimax search, then layering on more and more of OpenTafl’s search optimizations, to verify that none of the search optimizations break the minimax equivalence4.
Extension searches
Strong chess engines do something called extensions: after searching the main tree to a certain depth, they find interesting positions among the leaf nodes—captures, checks, and others—and search those nodes more deeply, until they become quiet5. OpenTafl does something similar, albeit on a larger scale. After it runs out of time for the main search, it launches into a two-stage extension search.
First, it attempts to deepen its view of the tree overall, a process I’ve been calling ‘continuation search’. Rather than clear the tree and start again, as OpenTafl does on its other deepening steps, continuation search starts with the tree already discovered and re-searches it, exploring to the next depth and re-expanding nodes. This process is much slower, in terms of new nodes explored, than a new deepening step, but as you’ll recall, deepening goes from left to right. A new deepening step discards useful information about the rightmost moves, in the hopes of discovering better information. Continuation search assumes that we don’t have the time to do that well, and that a broad, but not exhaustive, search to the next depth is more correct than half of a game tree6.
Continuation search takes time, too, though. It has to muddle its way down through the preexisting tree, potentially expanding lines of play previously discarded, before it gets to any truly new information. When there isn’t enough time for continuation search, the AI does something I’ve been calling horizon search, which resembles the traditional extension searches found in chess engines. The AI repeatedly makes deeper searches, using the end of the best nodes as the root. Frequently, it discovers that the variation it thought was best turns out not to be: I’d put it at about half the time that horizon search runs, discovering some unrealized weakness in the position that the evaluation function did not correctly account for.
But then again, it isn’t the evaluation function’s job to predict the future. The history of traditional game-playing AI is one of a quest for greater depth; a simple evaluation function and a deep search usually gives better results than a heavyweight evaluation function and a shallow search. With this philosophical point I think I will leave you for now. I have at least one more of these posts running later in the week, so I’ll see you then.
1. Hence minimax: one player is traditionally known as max, whose job it is to maximize the value of the position evaluation function, and the other is known as min, whose job is the opposite. The best move for max is the move which allows min the least good response.
2. Or whatever other natural ordering you prefer.
3. Or a move with the same score.
4. Since minimax is known to produce the optimal move from a given situation, any search which is not the same as minimax is no longer optimal. It turned out that, depending on the search optimizations, moves might be considered in a different order, and in case of identical scores, the first one encountered would be selected. The test runs from the start, so there are eight symmetrical ways to make the same move, and some searches came up with mirrored or rotated moves. Out of the bargain, I got methods to detect rotations and mirrors of a given move, which will serve me well for the opening book and the corner books I hope to do down the road.
5. Another point where chess AI developers have an edge on tafl fans: there’s more research on what makes for a quiet chess position (one where the evaluation is not likely to dramatically shift) than there is for tafl positions.
6. This was the source of a particularly pernicious bug, because it evaded most of my tests: most of the tests had search times just long enough to get near the end of the tree for a given depth, and the best move occurred at the start of the search in the rest. Continuation search also caused another bug, in response to which I wrote the AI consistency test. (I told you I wasn’t going in chronological order here.) That one was all my fault: I have a method to revalue the parents of a node, which is important for the next kind of search I’ll be describing. I was calling it after exploring the children of any node, propagating alpha and beta values up the tree too fast and causing incorrect, early cutoffs (which meant that the AI failed to explore some good countermoves, and had some baffling weaknesses which are now corrected).