(Sigh. Me having a very upset stomach and not being able to go to a match means you get multiple posts from me today. Lucky you, dear reader.)
I’ve seen some posts out there about things like “Are my revolvers still cool?”, “wheelguns suck”, “I don’t like lever guns”, “No, you’re wrong, lever guns are amazing”, “wheelguns are the best or you’re wrong!”, and the like. And now I’m going to weigh in on all this nonsense.
Right now, on my hip, is a Glock 34 with Surefire X300U-A. 17+1 capacity, loaded to bear with 124 grain 9 mm +P Gold Dots from Speer. I love this thing. It shoots great, conceals well with my normal mode of dress (read: loose fitting t-shirts and cargo pants). Hardcore, serious firepower. Also a total gamer gun. I picked this because I can conceal it (it’s about as big as a government model 1911) and I shoot it well. I have some other buddies who conceal a Glock 34 too, and some others who don’t. I don’t care, because it works for me, and that’s what matters. It is nice to be able to compare notes with some other guys though.
Glocks have a lot of advantages. They’re simple, reliable pistols. You can completely detail strip them with a 3/8″ punch. Magazines are cheap and plentiful, and hold lots of bullets. Everybody makes things for Glock. You can get whatever sights you want for your Glock. It’s pretty easy to get drop in trigger improvements, if that’s your thing. Modern 9 mm hollow points work about as well as any standard pistol caliber in terms of stopping power. And its soft shooting and cheap.
On my desk in front of me is something old school. My S&W Model 29, with the 6″ barrel, in .44 Magnum. It’s currently unloaded. I could conceal it if I want to (yes I have a holster for it), but I don’t. I think my Glocks, even my big 34, work better for carry. The Glock is lighter, narrower, holds three times as many bullets, and is easier to get good follow up shots with.
Now, if I lived in Alaska, or spent a lot of time outdoors, I might value being able to shoot big .44 magnum rounds at bears. I can stop a bear with 9 mm, but it’s easier to do it with .44 Magnum. That said, I’m in Western Pennsylvania, and I don’t hang out in bear country much. It’s not normally a big concern for me.
I bought the Model 29 back when I lived in upstate New York. I didn’t buy it for carry. That’s ok. Not all of my handguns are carry guns. I bought the Model 29 because it’s cool, and pretty, and it’s fun to shoot. Nothing brings a smile to my face faster than shooting a big bore revolver that I am confident I can control, and that’s my Model 29. I don’t care that I have better choices for carry. It’s ok. I like it anyway. I like all of my guns.
Revolvers aren’t the best choice from a military perspective, it’s true. Or if you’re in the bad-guy engaging part of cop work. Semiautos carry more bullets, reload faster, and are easier to repair when parts break. The inside of a revolver looks a lot like an old wind-up watch. Complicated. Not easy to figure out. A Glock is the kind of thing that you can repair really easily.
But, what about for the concealed carrier? It probably doesn’t matter. The most common gun fights (statistically), for a civilian with a concealed carry permit or an off-duty cop are over in about three gunshots. Three shots. My Model 29 holds twice that. Even a j-frame has a decent two-shot margin on that. Rule One of a gunfight is HAVE A GUN. Pick one that suits you. How you tend to dress. Where you tend to go. Carry something you feel comfortable with. Carry something you practice with. And hell, carry something you like. Emotional attachment will help make sure you keep that gun with you. Whatever works.
CARRY YOUR FUCKING GUN.
Tom Givens, firearm instructor, has a wonderful body of shooting statistics from former students. All of his students who had guns on them in their altercations won. The only students who ended up in a bad way were those who didn’t have their guns on them when they were accosted.
So, while less effective than a semiauto, revolvers can still work for you. If you do your part. I’m not the biggest fan of revolvers, but I’m not you. If it works for you, rock on with your bad self. I’m gonna keep carrying my Glock 34, because I like it. Even if it’s a Gamer Gun, it’s probably not going to get me killed on Da StreetzTM.
I’m gonna say the same thing about lever action guns and bolt action guns if anybody asks. Know what’s great about capitalism? You can buy whatever the fuck you want. So can I. I’m gonna buy guns I like, for whatever reason. I don’t care if you don’t like them. They’re not your guns. I think people really ought to harden up a bit about this nonsense. Doesn’t matter if everybody in the 14th Chairborne Ranger Regiment does or doesn’t like your choices. They can pick their things. Be an adult. Go pick yours.
I don’t know what your preference is, but I know two things. One, there’s somebody out there who thinks it’s dumb and that it will get you killed or some nonsense like that. Two, there are others out there who think like you do.
We’ve spent some time earlier talking about remote turrets in our analysis of the Land 400 finalists. The German Lance turret is a pretty solid design. The Russians have a fancy new remote turret too. They don’t need to make a design with a bunch of different option s for export, so they settled on a somewhat different feature set. It’s in use on the T-15 Armata Heavy IFV and the Kurganets 25 IFV, so let’s take a look.
Unlike most other remote turrets, this new turret, called the Epoch, is pretty big. Russian big. It also contains a whole bunch of lessons from Russian experiences in Chechnya, as well as American experiences in Iraq. Epoch holds ATGMS, a 30×165 mm cannon and a 7.62x54R mm machine gun. And it’s loaded with ammo. The Bradley’s designers would be proud and jealous. There are 500 (no that’s not a typo) ready rounds of 30 m ammo, plus 2,000 ready rounds of 7.62x54R. Lots of ammo is good. The Russians have tended towards large ammo capacities, and just in case they had second thoughts, watching the American Bradleys go Rambo with their 300 rounds of 25 mm in Iraq convinced them that combining an HE firehose with staying power is aweseome. Reloading is for chumps. For the 30 mm, there’s a 340 round magazine and a 160 round magazine, and a dual-feed system for the 24A2 autocannon. We’d expect the bigger magazine to hold HE.
The autocannon and the coaxially mounted machine gun are both biaxially stabilized, and the turret is electrically driven. More interestingly, the Epoch is designed for high angle fire. This isn’t for indirect fire, this is because the Russians remember insurgents in Grozny hiding on the upper floors of buildings. That’s no place to hide now.
Additionally, the Epoch has provision for four Kornet-EM launchers, with two tubes on either side of the turret. I’m somewhat torn here. On the one hand, these are modern missiles, and four is the right number of missiles. More is better. On the other hand, while it has a relatively large tandem warhead, the Kornet is a laser-beam riding, SACLOS-guided missile that takes a direct flight path. It isn’t top-attack, and that’s just lame. Javelin or Spike would be better here. Even the newest TOW model, the TOW-2B, has an overflight top-attack profile. I really don’t like the idea of directly attacking enemy armor, now that the turret might automatically be rotated to present the strongest armor, and how light composite arrays and multilayer ERA arrays are getting. We’ve just had a nasty urban warfare campaign in Iraq which has convinced everybody to augment the side armor of their tanks. Time for some cleverness in your missile design, KBP.
The Epoch has two obvious sighting units, one for the gunner and an independent one for the commander. They appear to have day and thermal viewing units plus laser rangefinders. I don’t know the magnification levels, and I also don’t know how good the thermal viewers are. Historically, this hasn’t been something the Russians are good at. I don’t know if the sensors are quietly being provided by the French, or if the Russians have finally figured things out. This is probably not a dealbreaker though; as I mentioned in the T-14 review, it’s easy enough to change these out.
Moving on to other questions, the protection levels aren’t published, and don’t appear to be all that heavy. Probably good against machine gun fire and shell fragments, but not much else. This is acceptable, given that it’s unmanned. More protection would be better so a support fires kill by enemy IFVs is harder to achieve. It’d be hard to augment it much further given how many systems are externally mounted.
Overall though, this turret is a really good design. I like built-in combat persistence, and most of my serious gripes would be easy enough to work around. Here’s another good, modern design.
The German court in Koblenz has found in favor of HK that they are not at fault for the issues plaguing the G36. This was expected, at least by yours truly. HK asserted in its lawsuit that the German government never required their rifles pass the tests in question, therefore they couldn’t be held liable for said rifle failing to meet those requirements. And it is true that the Bundeswehr never had requirements regarding the failures in question. Nor indeed did they do the tests until the chorus from the troops became so loud that they could not be drowned out. A good, legalistic defense. And good news for HK.
And let me be clear. I’m not blaming them for failing to meet standards they weren’t tested for. You might be a trifle peeved at HK if you’re following the news, but how would you feel if you took a high school Algebra test and then your parents scolded you for failing to pass a calculus exam?
What were the problems? To put it mildly, the G36 sucks when exposed to heat. The barrel is mounted to the polymer receiver and the polymer sight assembly in such a way that heat will compromise the mount, causing accuracy issues. I am not sure if this is a question of structural engineering or polymer composition or both.
Here is a picture of the trunnion on the G36.
That area, of course, is right around the chamber of the rifle. It’s gonna get hot quick. Now, I’m no engineer, but that doesn’t seem all that sturdy of a mounting method. And I might be curious as to how hot that area gets. And I know no other rifle does things that way.
These issues can be found in as little as 90 rounds (three magazines) of automatic or reasonably quick semiautomatic fire. They are also significantly exacerbated by high temperatures. The kind you might find in the Middle East. You can imagine the shock and horror in the Bundeswehr when they finally went out to go kick some haji ass with their American (and French!) pals and discovered that their rifles couldn’t take the heat.
Now, Germany is a temperate place. But the Germans have been in warm places before. Where? Hmm. Well, there was that bit in Afrika back in the 40s, right?
NEIN! DISCUSSION OF THE WAR IS STRENG VERBOTEN!!
Okay. So, maybe not. I imagined Rommel. But hey. When 90 or so shots make your targets look like you forgot how to shoot all of a sudden, there’s no trouble at all, right? We’re imagining things.
But don’t take my word for it. I’m just some Amerikaner. What do I know? What do the German special forces units use? They use the HK 416 as much as they can. Hmm. Aluminum receiver, eh? I think my police friends might call this a “clue”.
German troops deployed to Afghanistan always tried to acquire G3s or HK 416s in the field. Another clue!
Then there’s the XM8, which was a G36 with a fancy shell. Same construction. It was plagued by heat issues, which caused its weight to skyrocket. Huh. This is turning into Cluetown over here.
Other than the massive heat issues, the G36 isn’t a terrible design. It looks kinda space age. It has an ambidextrous charging handle and ambidextrous safeties. The mag release is a paddle (which is in the center, and therefore also ambidextrous), and the mags do not drop free. The paddle isn’t operable by the strong hand from its usual position on the firing grip. It’s not as nice as an AR-15 pattern weapon ergonomically. The gas piston system works well. The magazines are also a good feature of the weapon. They can be clipped together using lugs on the side. They are also made of a translucent polymer, so you can see how many rounds remain. Plus, they were designed from the start for thirty rounds, so they have a continuous curve, instead of the dogleg of the AR-15 magazine. The optics are kinda goofy, and they’re integral, so have fun with that. The compact G36C version would introduce a lower picatinny rail sight/carry handle. But not as low as on other not-G36 rifles, because the charging handle is right there under the carry handle.
Also, in case there was doubt, the HK 416 is basically HK’s take on the AR design, but with the G36 op rod system. So there’s that, and it’s way better. Imitation is the sincerest form of flattery. They’re clearly paying us Americans back for stealing the Mauser design for the Springfield 1903.
Overall, the G36 a meh rifle before we knew about the heat problems, and now I can’t imagine why you’d get one. Despite all of the fancy new-age polymers, the regular G36 rifle isn’t lighter than the M16A2 (or M16A1, which is lighter still). And the M16A2 won’t make your groups the size of a barn after 90 rounds.
The French are not wasting any time in selecting a replacement for their worn-out FAMAS rifles. The HK 416 has been selected as the new French Service rifle, beating out the other downselected rifle, the FN SCAR 16.
Let’s review salient points in the 416’s favor, in case you’re wondering why the French picked a gun from La Boche. I’ve got some more thoughts on the 416 itself, but those will wait. This is about France.
1.) The HK 416 has been chosen as a general issue rifle already, by Norway. The SCAR 16 has not. While both were developed by American special operations units, and both are in service with a number of special operations groups around the world, including some in France, there’s a lot you can learn from a rifle by giving it to a bunch of grunts to use and abuse. Grunts can break everything. And the Norwegians have found some minor issues, which HK has fixed. So that’s a bunch of bugs the French won’t find. Picking something someone else has already issued generally means you’ll find fewer problems.
2.) The HK 416 is going to be the G36 replacement. Only a matter of time. I’ll have more on the G36 later this week, but given the problems it has in the heat (even if no one in cold-ass Germany thought to test in the heat), the Germans will be ditching the G36. The winner is going to be German, because they’re still secretly nationalist. And that means it’s going to be the next service rifle of Germany.
Why does this matter for France? Well, France is trying to cooperate a lot more with Germany on military matters. They’ve got a bunch of projects in the works with Germany, including a new tank project. Even if I think multinational projects like that are a terrible idea, and no multinational tank project has ever actually delivered anything, they’re committed. So choosing a common service rifle is a no brainer.
3.) The HK 416 is very automatic-rifle-like. Remember, in its off the shelf form (ok, they nicely put USMC on the side), the 416 was selected as the Squad Automatic Rifle for the US Marine Corps, in sort of a modern-BAR type role. I’m not sure if this is important to you, but if it is, if you’re worried about battles like Wanat (and can’t just fix your officer corps), the 416 is the rifle for you. It is also heavy. If you like heavy, it’s the rifle for you.
So there you have it. That said, I’d still prefer a more traditional direct impingement M4, maybe from Colt, or maybe Colt Canada (they actually have a somewhat different catalog than regular Colt), or LMT.
This is the third article in a series of posts on OpenTafl. You can read the first and second parts at the preceding links.
Welcome back to the third and final entry in Opentaflvecken, a one-week period in which I provide some minor respite to poor parvusimperator. We’ve hit the major AI improvements; now it’s time to cover a grab bag of miscellaneous topics left over. Onward!
Playing out repetitions In OpenTafl’s versions of tafl rule sets, threefold repetitions are invariably handled: by default, it yields a draw; some variants define a threefold repetition as a win for the player moving into the third repetition of a board state1. Prior to the AI improvements release, the AI simply ignored repetitions, an obvious weakness: if you found a position where you could force OpenTafl to make repeated moves to defend, you could play the forcing move over and over, and OpenTafl would obligingly find a different way to answer it until it ran out and let you win. No longer! Now, OpenTafl is smart enough to play repetitions out to the end, using them to win if possible, or forcing a draw if necessary.
It turns out, as with everything in AI, this is not as simple as it sounds. The problem is the transposition table. It has no information on how many times a position has been repeated, and repetition rules introduce path dependency: the history of a state matters in its evaluation. Fortunately, this is a very simple path dependency to solve. OpenTafl now has a smallish hash table containing Zobrist hashes and repetition counts. Whenever a position appears, either in the AI search or in the regular play of the game, the repetition count is incremented. Whenever the AI finishes searching a position, it is removed from the table. In this way, at any given state, the AI always knows how many times a position has occurred. If the position has occurred more than once in the past, the AI skips the transposition table lookup and searches the position instead. This seems like it might cause a search slowdown—repetitions can no longer be probed—but in practice, it’s turned out to have almost no effect.
Move ordering improvements I discussed move ordering a little bit in the second article, but I want to go into a little more depth. Move ordering is the beating heart of any alpha-beta search engine. The better the move ordering, the better the pruning works; the better the pruning works, the deeper the AI can search; the deeper the AI can search, the better it plays. Early on in OpenTafl’s development, I threw together a very simple move ordering function: it searched captures first and everything else later. Later on, after the transposition table went in, I added a bit to try transposition table hits in between captures and the remaining moves. The move ordering used Java’s sort method, which, though efficient, is more ordering than is necessary.
Late in the AI improvements branch, when I added the killer move table and the history table, I decided to fix that. Move ordering now does as little work as possible: it makes one pass through the list of moves, putting them into buckets according to their move type. It sorts the transposition table hits and history table hits, then searches the killer moves, the history table hits, the top half of the transposition table hits, the captures, the bottom half of the transposition table hits, and finally, any moves which remain. Though there are two sorts here instead one, since they’re much smaller on average, they’re faster overall.
Puzzles Okay, this one isn’t exactly an AI feature, but you’ll note that the title doesn’t limit me to AI future plans only. It also turns out that this isn’t much of a future plan. Puzzles are already done on the unstable branch, so I’ll use this section to tell you about the three kinds of puzzles.
The first is the least heavily-annotated sort, the one you might find on the hypothetical chess page of a newspaper: simply a rules string, a position string, and a description along the lines of ‘white to win in 4’. OpenTafl supports these with the new load notation feature: paste an OpenTafl rules string into a dialog box, and OpenTafl will load it. (There’s also a new in-game/in-replay command which can be used to copy the current position to the clipboard, ctrl+c and ctrl+v being nontrivial for the moment.)
The other two are closely related. They start with a standard OpenTafl replay, then use some extra tags to declare that the replay file defines a puzzle, and tell OpenTafl where in the replay file the puzzle starts. The puzzle author uses OpenTafl’s replay editing features to create variations and annotations for all of the branches of play he finds interesting, then distributes the file. When loading the file, OpenTafl hides the history until the player explores it. The two closely-related kinds I mentioned are loose puzzles and strict puzzles, the only difference being that loose puzzles allow the player to explore branches the puzzle author didn’t include, while strict puzzles do not.
OpenTafl has all the tools you need to author puzzles, although, at present, you will have to do your own position records. (Sometime down the line, I’d like to add a position editor/analysis mode, but today is not that day.) The README will have more details.
You can expect two or three puzzles to ship with the OpenTafl v0.4.4.0b release, along with all puzzle-related features.
Future evaluation function plans I mentioned before that there are some weaknesses in the current evaluation function, and that some changes will be required. I’m becoming more convinced that this is untrue, and that what I really ought to do is an evaluation function which is easier for humans to understand. The current evaluation function just places an abstract value on positions; the one I’d like to do uses the value of a taflman as an easy currency. In doing so, I can ask myself, “Would I sacrifice a taflman to do X?” Having that as a check on my logic would be nice, and would prevent me from making dumb logic errors like the one in the current evaluation function, where the attacker pushes pieces up against the king much too eagerly.
This may also require more separation in the evaluation function between different board sizes; sacrificing a taflman in a 7×7 game is a bigger decision than sacrificing one in an 11×11 game. I may also have some changing weights between the opening and the endgame, although, as yet, I don’t have a great definition for the dividing line between opening and endgame.
Anyway, that’s all theoretical, and undoubtedly I’ll be writing about it when I get to it, as part of the v0.4.5.x series of releases. In the meantime, though, I have plenty to do to get v0.4.4.0b done. I’ll be testing this one pretty hard, since it’s going to be the next stable release, which involves a lot of hands-on work. The automated tests are great, but can’t be counted on to catch UI and UX issues.
Thanks for joining me for Opentaflvecken! Remember, the AI tournament begins in about three and a half months, so you still have plenty of time to hammer out an AI if you’d like to take part. Hit the link in the header for details.
This isn’t exactly intuitive, but the person moving into a state for the third time is the person whose hand is forced. (Play it out for yourself if you don’t believe me.) Although it’s traditional to declare a threefold repetition a draw, I think it works better in tafl if the player making the forcing move is forced to make a different move or lose.
I am not a rocket scientist, but I do like to think about engineering problems.
Here are the facts as we know them:
A Falcon 9 rocket blew up on the pad on September 1, 2016.
The rocket was undergoing a pre-launch static test, when it exploded.
According to SpaceX, the explosion originated in the second-stage liquid oxygen tank.
SpaceX uses a fancy super-cooled LOX mix, which allows more fuel in a given tank volume, which allows better performance.
Last summer, SpaceX had another rocket fail. The CRS-7 mission disintegrated in flight after the upper stage LOX tank burst. The internal helium tank (to maintain tank pressure) failed because of a faulty strut.
Now, for a rocket to fail during fueling, before engine firing—as the most recent Falcon failed—is very unusual. To my engineer’s mind, it suggests a materials problem in the LOX or liquid helium tanks, something failing in an unexpected way when deep-chilled. Crucially, the Falcon 9’s LOX tank experiences the coldest temperature (for a LOX tank) in the history of rocketry. Take that in combination with the failure on the CRS-7 mission: after their investigation, SpaceX switched to a new strut, which means new failure modes.
Mark my words (and feed them to me along with a heaping helping of crow, when I turn out to be wrong): this is another strut issue, be it faulty or just unsuited for the deep-cryo fuel in some other way.
This is the second article in a series on AI improvements to OpenTafl. Read the first part here.
Welcome back! In the first article in this series, I talked about what was, essentially, groundwork. I did gloss over two rather large bugs in the course of that article, so I’ll give them a deeper treatment before I dive into the three topics I have planned for today.
First: I failed altogether to mention a bug that cropped up while I was writing continuation search, and which, in actuality, prompted my creation of the AI consistency test. I have a bit of code around for extension searches (that is, searches that begin from a non-root node), whose purpose is to revalue all of the nodes above it. I was calling that method much too frequently, even during the main search, which pushed child values up the tree much too quickly, and yielded incorrect alpha-beta values. The bounds converged too quickly, and I ended up cutting off search far too early, before the search had verified that a certain move was safe in terms of opponent responses. I ended up designing a miniature tafl variant, 5×5 with a total of four pieces all limited to a speed of 1, to diagnose the issue. As a game, it’s unplayable, but the game tree to depth 3 takes about 30 or 40 lines, and it’s easy to read the tree and see what’s happening. That’s what I did, and that’s how I found my problem.
Second: the incomplete tree search bug, which I covered in a small amount of detail in a footnote. This one dates back to the very beginning of the OpenTafl AI, and is likely the cause of most of its weaknesses and obvious misplays since then. As I said in the text and the footnote, it stemmed from the assumption that a partial search of, for instance, depth 6 was better than a full search of depth 5. The true trickiness of this bug is that a partial search of depth 6 is, indeed, often as good as a full search of depth 5. All alpha-beta AIs prefer to search the best moves first, so if OpenTafl gets a little ways into the tree, a partial search at depth 6 is good enough to match the full search at depth 51.
The really awful part of this bug, the one which made it the most inconsistent, was that OpenTafl doesn’t always manage to assign a value to every state when it’s out of time. The states have a magic number value marking them as having no evaluation: -11541. This value ended up in the game tree, and it’s a very tempting move for the defender. Subtrees the defender had not finished exploring would be chosen over subtrees it had, leading to inconsistent and incorrect behavior. The solution, as I mentioned in the previous post, was, when starting search to a new depth, to save the search tree to the previous depth. If the new depth doesn’t finish, OpenTafl uses the complete tree from the previous depth.
Time use planning That brings me quite naturally to my first new topic for today: time use planning. Getting time usage correct is tricky. Obviously, we want to search as deeply as possible in the main tree, but we also want to stop as soon as we know we can’t search to the next depth. Since we discard incomplete searches, any time spent on an unfinished search is wasted. Unfortunately, ‘can we search to the next depth?’ carries with it a good deal of uncertainty. OpenTafl now uses a few tricks to determine whether it should attempt a deeper search.
First, it better takes advantage of previous searches to a given depth. Concrete information is hard to come by for AIs, and ‘how long did it take me to do this last time?’ is pretty darned concrete2. Whenever a search is finished to a given depth, OpenTafl stores the time that search took in a table and sets the age of that data to zero. Whenever a search to a given depth fails, OpenTafl increments the age of the data for that depth. If the age exceeds a threshold, OpenTafl invalidates all the data at that depth and deeper.
When determining whether to embark on a search to the next depth, OpenTafl first checks the table. If it has data for the desired depth, it compares its time remaining to that figure. If there is no data, it synthesizes some. Obviously, we know how long it took to get to the current depth: we just finished searching to it. OpenTafl takes two factors into account: first, it’s hard to search to the next depth; and second, it’s harder to search to an odd depth than an even depth3. If going to an even depth, OpenTafl assumes it’ll be 10 times as hard as the previous depth; if going to an odd depth, OpenTafl assumes 20 times. These numbers are extremely provisional. Sometime down the line, I want to write some benchmarking code for various depths and various board sizes to generate some data to make those factors resemble reality more closely.
Second, OpenTafl reserves some time for extension searches. Horizon search oftentimes changes the end result of the evaluation, and so OpenTafl seems to play better when it has time to run. About 15% of the total think time for any given turn is set aside for extension searches.
Search heuristics #1: the history heuristic On to the heuristics! I implemented two for this release. The first, the history heuristic, is one of my favorites. Much like dollar cost averaging4 in finance, the history heuristic says something which is, on reflection, blindingly obvious about alpha-beta searches, but something that nevertheless is not immediately apparent. It goes like this: moves which cause cutoffs, no matter where they appear in the tree, tend to be interesting, and worth exploring early.
Consider the game tree: that is, the tree of all possible games. It fans out in a giant pyramid shape, ever widening, until all of the possibilities peter out. Consider now the search tree: a narrow, sawtoothed path through the game tree, approaching terminal states until it finally alights upon one. The search tree always examines a narrow path through the tree, because the full game tree is so overwhelmingly large. Since the search tree examines a narrow path, similar positions are likely to come up in many different searches, and in similar positions, similar moves are likely to cause cutoffs. Therefore, whenever a move causes a cutoff, we ought to keep track of it, and if it’s a legal move in other positions, search it earlier.
That’s about all there is to it: the bookkeeping is a little more complicated, since we have to do something to be sure that cutoffs high up in the tree are given as much weight as cutoffs lower toward the leaves (OpenTafl increments the history table by remainingDepth squared), but that isn’t especially important to understand the idea.
There are two variations on the history heuristic I’ve considered or am considering. The first is the countermove history heuristic. The history heuristic in its simplest form is very memory-efficient: you only need table entries; OpenTafl’s table entries are simple integers. Even for 19×19 tafl variants, the total size is less than half a megabyte. There exists a more useful expansion of the history heuristic sometimes called the countermove-history heuristic, which involves adding another two dimensions to the table: save cutoff counts per move and preceding move. This allows for a closer match to the situation in which the cutoffs were previously encountered, and increases the odds of a cutoff, but it turns out the inefficiency is too great in tafl games. Chess, with its more modest 8×8 board, can afford to bump the table entry requirement up to : it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case, , or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.
So I did some further reading on the subject, then came across another relation of the history heuristic: the relative history heuristic. It combines a plain history heuristic with something called the butterfly heuristic, which counts how many times a given position occurs in the tree. The relative history value of a state is its history heuristic value (the number of cutoffs it has caused) divided by its butterfly value (the number of times it has appeared in the tree). This makes the relative history heuristic a measure of the efficiency of a move: if a move appears ten times in the tree and causes ten cutoffs, it’s probably more interesting than a move that appears ten thousand times in the tree but only causes eleven cutoffs. I haven’t gotten around to it yet, but OpenTafl will probably include the relative history heuristic in a future AI release.
Search heuristics #2: the killer move heuristic The killer move heuristic is the other heuristic I implemented for this release. The killer move heuristic is a special case of the history heuristic5, and turns out to be the single greatest improvement in OpenTafl’s strength I’ve implemented to date6.
What is it, then? Simply this: for each search, it tracks the two first moves which caused a cutoff at a given depth, along with the most recent move to do so, and plays those first whenever possible. See? Simple. It calls for very little explanation, and I’m already at nearly 2,000 words, so I’ll leave you with this. See you later this week for the thrilling conclusion.
Advanced chess engines take advantage of this fact to search deeper: they do something called ‘late move reduction’, where the moves late in the move ordering are searched to a lesser depth, leaving more search time for the better moves (the ones earlier in move ordering). Move ordering in chess engines is usually good enough that that this works out.
It isn’t always useful, though. Depending on what happens on the board and how well the move ordering happens to work, relative to the previous search, the next search may be very fast (if it’s something we expected) or very slow (if it completely blows up our plan).
Even depths are usually small and odd depths are usually large, in terms of node counts relative to what you’d expect if the increase was linear. The mechanism of alpha-beta pruning causes this effect.
Dollar cost averaging makes the incredibly obvious observation that, if you put money into an asset over time, fixed amounts at regular intervals, you end up buying more of the asset when the price is low than when the price is high. Because of numbers.
Although the literature usually reverses this relationship: the history heuristic is normally referred to as a general case of the killer move heuristic, since the latter was used first.
In two ways: first, the version with the killer move heuristic plays the best against other AIs; second, the version with the killer move heuristic deepens far, far faster. The killer move heuristic is, in fact, almost single-handedly responsible for that faster speed to a given depth, going by my benchmarks. In brandub, for instance, OpenTafl reaches depth 6 in 2.5 million nodes without the killer move heuristic, and 1.3 million nodes with it. Searching killer moves first yields the best result, and moving anything ahead of them in the search order is non-ideal.


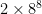 : it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case,
: it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case, 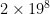 , or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.
, or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.