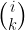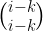I mentioned in a previous post that one of the practical difficulties involved in computer implementations of tafl is the lack of a support infrastructure: anyone desiring to write a tafl AI must also write a tafl engine. Admittedly, this probably isn’t a significant obstacle to anyone with a real desire to write a tafl AI, but it does yield a great deal of duplication of effort. This is why my next step with OpenTafl is to build it into an engine into which other AIs can be plugged, and my eventual aim, hopefully at the end of this year, is to host the world’s first computer tafl tournament, where all the AIs so far written can compete against one another for bragging rights1. The timing depends mainly on how quickly I can write the features I need, but I hope to run the 1st Many Words Computer Tafl Open in late December2.
To do this, though, three sorts of notation are required. First, a method for communicating positions; second, a method for communicating rules; and third, a method for communicating moves. (A method for communicating moves already exists, thanks to tafl historian Damian Walker, but I propose some enhancements to it later.) The full version of my proposal is included at the end of this post.
First off, a method for positions: I propose something akin to chess’s Forsythe-Edwards notation, which is easily machine-readable, but also human-readable, and easy to compose by hand. Here’s an example, representing the brandub starting position:
/3t3/3t3/3T3/ttTKTtt/3T3/3t3/3t3/
Enclosed by slashes are rows. Lowercase letters represent pieces from the attacking side. Uppercase letters represent pieces from the defending side. (Besides t: taflman and k: king, my proposal also includes n: knight and c: commander, for Berserk-variant tafl.) Numbers represent that many empty spaces.
To communicate rules, there’s very little choice but to do so exhaustively. Clever use of defaults can somewhat alleviate the issue. Here is a proposed OTN rules string for Fetlar tafl:
dim:11 atkf:n start:/3ttttt3/5t5/11/t4T4t/t3TTT3t/tt1TTKTT1tt/t3TTT3t/t4T4t/11/5t5/3ttttt3/
It uses the dimension element (dim:11) and the start element (using an OTN position string) to mark the start and end of the rules; other elements come in between. The defaults suggested in the proposal, with the exception of atkf (attackers move first), are the rules of Fetlar, and other tafl games may be constructed as transformations from Fetlar. For instance, here’s brandub again:
dim:7 ks:n cenhe:n cenh: cenp:tcnkTCNK start:/3t3/3t3/3T3/ttTKTtt/3T3/3t3/3t3/
Brandub is Fetlar, except it’s played on a 7×7 board (dim:7), the king is not strong (ks:n), the center does not become hostile to the defenders when empty (cenhe:n), the center is not hostile to anybody (cenh:), and pieces of all types may pass over the center space (cenp:tcnkTCNK). Here’s Sea Battle 9×9:
dim:9 esc:e ka:n cenh: cenhe:n corh: cenp:tcnkTCNK corp:tcnkTCNK cens:tcnkTCNK cors:tcnkTCNK start:/3ttt3/4t4/4T4/t3T3t/ttTTKTTtt/t3T3t/4T4/4t4/3ttt3/
Sea Battle is Fetlar, except it’s played on a 9×9 board, escape is to the edge (esc:e), the king is not armed (ka:n), the center and corners are hostile to nobody, all pieces may move through the center and the corners, and all pieces may stop on the center and the corners.
Of tafl variants of which I am aware, the options in the rules string are sufficient to support all of them but one very esoteric alea evangelii variant3, and OpenTafl can theoretically support any variant constructed using OTN rules strings4. Other notable capabilities include the ability to define certain spaces as attacker fortresses, to support hostile attacker camps.
Finally, we move on to move notation. Building on Damian Walker’s aforementioned, excellent adaptation of algebraic chess notation to tafl rules (which, I should stress, is more than sufficient), I wanted to create a notation which requires a minimum of inference, and therefore slightly better suited to inter-computer communication. In effect, I wanted a notation sufficiently detailed such that a computer, operating with only a starting position and a list of moves, could accurately replay the game without having to know any of the rules. Since it is a notation with a lot of options, I provide a deeply contrived sample move record here, which uses almost every option:
Ne4-e6xf6 Ne6^=e8xe7/e9/cf8/d8-
The defending knight (uppercase N) on space e4 moves to e6, capturing the piece on f6 (having no special letter, it’s just an ordinary taflman). This is berserk tafl, so the move is not yet over. The knight on e6 jumps to e8 as its berserk move (^: jump, =: berserk), capturing the taflmen on e7, e9, and d8, and the enemy commander on f8 (as a special piece, it gets a prefix; as an attacking piece, it’s lowercase). This opens up a path for the king to reach the edge (-: king has a way to the edge).
You can read more, and peruse more examples, in the full proposal here: OpenTafl Notation. Feel free to leave a comment with your, well, comments.
1. And maybe a $20 Amazon gift card or something.
2. I hope to finalize the protocol in the next few months, and finish implementing it by the end of summer.
3. The one with mercenaries, pieces which start on the defending side but change sides when captured.
4. I haven’t yet written the code to parse them and generate new games, so I can’t say for sure. Thinking through some oddball variations, though, none strike me as OpenTafl-breaking.


![\displaystyle\sum_{i=3}^{37} \Bigg(\binom{121}{i} \times \bigg(\sum_{k=1}^{i-1} \binom{i}{k} \times k\bigg)\Bigg) \\[1em] \approx 1.4\times10^{43}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%5Csum_%7Bi%3D3%7D%5E%7B37%7D+%5CBigg%28%5Cbinom%7B121%7D%7Bi%7D+%5Ctimes+%5Cbigg%28%5Csum_%7Bk%3D1%7D%5E%7Bi-1%7D+%5Cbinom%7Bi%7D%7Bk%7D+%5Ctimes+k%5Cbigg%29%5CBigg%29+%5C%5C%5B1em%5D+%5Capprox+1.4%5Ctimes10%5E%7B43%7D&bg=ffffff&fg=000&s=1&c=20201002)