Over on Instagram, I did some careerstatistics using USPSA Analyst. Since the data I have easy access to is for major matches only, and a date-limited set besides, those ‘career’ statistics were necessarily partial.
Now that the latest version of USPSA Analyst is released, you can run career statistics for yourself, including every match you’ve shot, locals too. Here’s how.
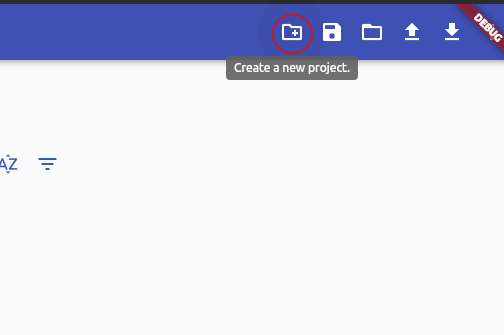
1. Go to the ratings configuration page (bottom right button on the home screen) and create a new project for your match list.
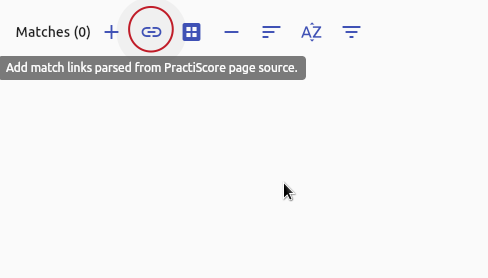
2. Select the ‘parse PractiScore page source’ option.
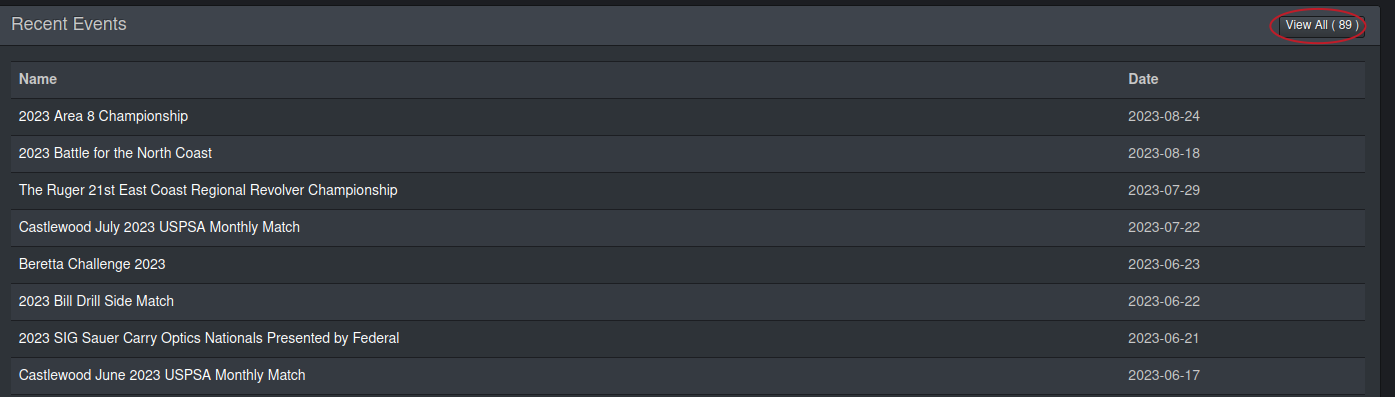
3. Go to your PractiScore dashboard and click the ‘View All’ button under ‘Recent Events’.
4. Right-click on the resulting page and click ‘view page source’.
To be sure you have the right page source, Ctrl+F to search for ‘matchid’ in the output.
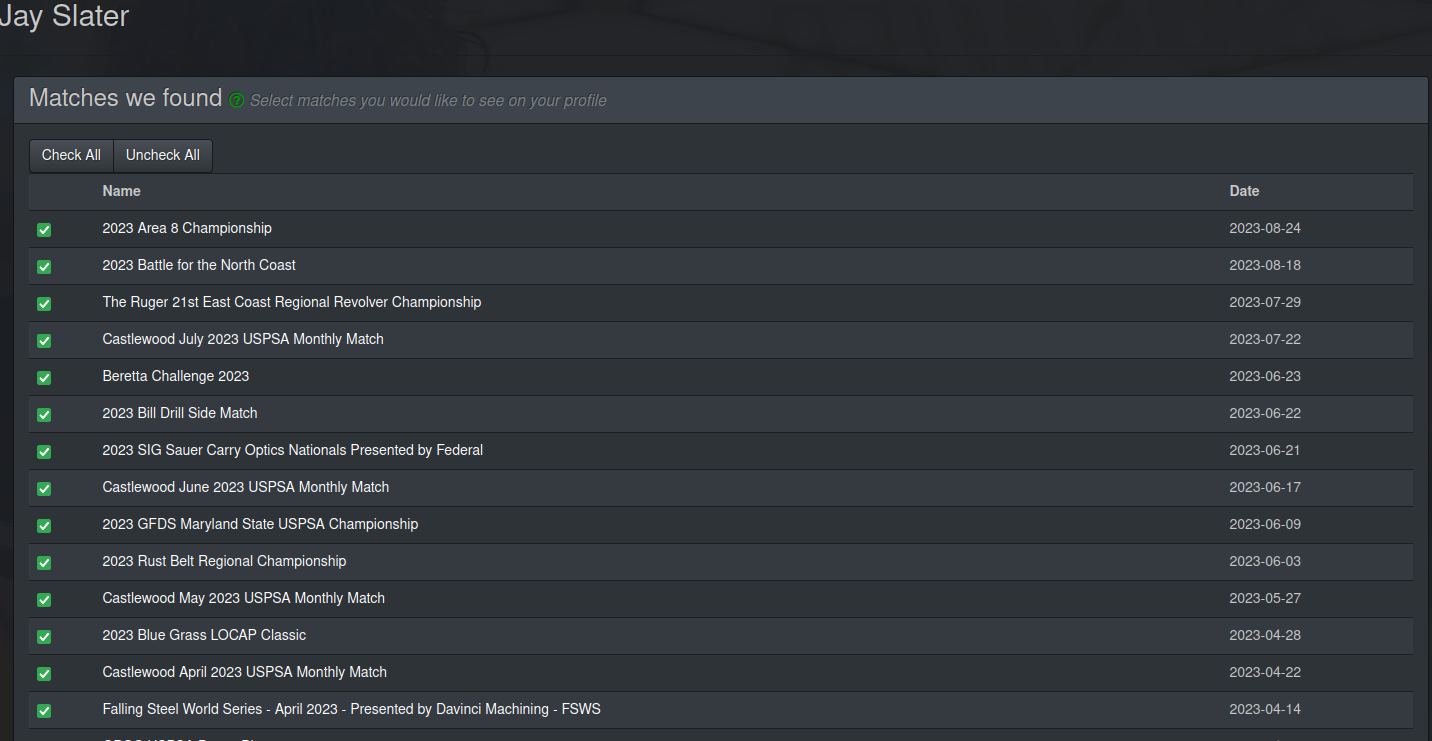
5. Copy and paste the page source into the dialog in USPSA Analyst.
6. If you have participated in multiple divisions and want to combine your statistics, tap the edit button next to ‘Active rater groups’.
Click ‘None’, then ‘Combined’.
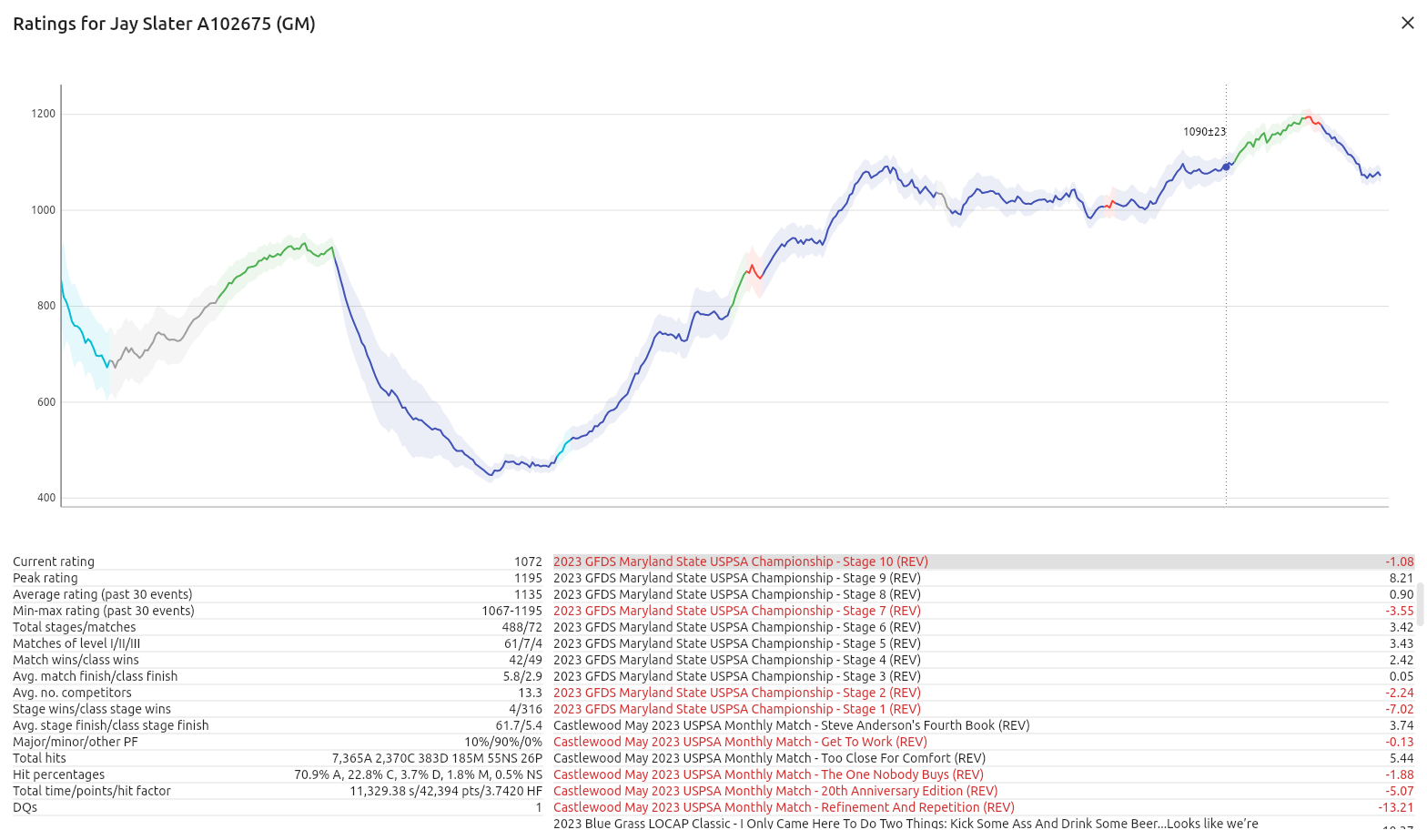
7. Click ‘Advance’, use the search box to find yourself in the ratings, click on your row, and enjoy your career stats.
In USPSA circles these days, I’m known in roughly equal measure for being ‘that East Coast revolver guy’ and ‘that Instagram Elo ratings guy’. This post is about the second topic. In particular, it’s a simple, mostly non-mathematical primer about Elo ratings in general, and Elo ratings as I have applied them to USPSA with the tool I call USPSA Analyst1.
This article is up to date as of September 2023. It may not be up to date if you’re reading it later on, and it may not be fully complete, either—this is not meant to be full documentation of Analyst’s guts (that’s the source code), but rather a high-level overview.
Elo basics
The Elo2 rating system was first developed to measure the skill of chess players. Chess is what we call a two-player, zero-sum game: in tournaments, each chess game is worth one point. If there’s a draw, the two players split it. Otherwise, the winner gets it. Elo operates by predicting how many points a player ought to win per game, and adjusting ratings based on how far the actual results deviate from its predictions.
Let’s consider two players, the first with a rating of 1000, and the second with a rating of 1200. The second player is favored by dint of the higher rating: Elo expects him to win about 0.75 points per game—say, by winning one and drawing the next, if there are two to be played. If player 2 wins a first game, his actual result (1 point) deviates from his expected result (0.75), so he takes a small number of rating points from player 1. Player 2’s rating rises, and player 1’s rating falls. Because the deviation is relatively small, the change in ratings is relatively small: we already expected player 2 to win, so the fact that he did is not strong evidence that his rating is too low. Both players’ ratings change by 10: player 2’s rating goes up to 1210, and player 1’s rating goes down to 990.
On the other hand, if player 1 wins, his actual result (1 point) deviates from his expected result (0.25) by quite a lot. Player 1 therefore gets to take a lot of points from player 2. We didn’t expect player 1 to win, so his win is evidence that the ratings need to move substantially to reflect reality. Both players’ ratings change by 30, in this case: player 2 drops to 1170, and player 1 rises to 1030.
The amount of rating change is proportional to the difference in rating between the winner and loser. In Elo terms, we call the maximum possible rating change K, or the development coefficient3. In the examples above, we used multiplied by the difference between expected result and actual result4: makes 10, for the rating change when player 2 wins, and makes 30, for when player 1 wins.
Expected score can be treated as an expected result, but in the chess case, it also expresses a win probability (again, ignoring draws): if comparing two ratings yields an expected result of 0.75, what it means is that Elo thinks that the better player has a 75% chance of winning.
There are a few things to notice here:
Standard Elo, like chess, is zero-sum: when one player gains rating points, another player must lose them.
Standard Elo is two-player: ratings change based on comparisons between exactly two players.
Elo adjusts by predicting the expected result a player will attain, and multiplying the difference between his actual result and expected result by a number K.
When comparing two ratings, Elo outputs an expected result in the form of a win probability.
Elo for USPSA
Practical shooting differs from chess in almost every way5. Beyond the facially obvious ones, there are two that relate to scoring, and that thereby bear on Elo. First, USPSA is not a two-player game. On a stage or at a match, you compete against everyone at once. Second, USPSA is not zero-sum. There is not a fixed number of match points available on a given stage: if you win a 100-point stage and another shooter comes in at 50%, there are 150 points on the stage between the two of you. If you win and the other shooter comes in at 90%, there are 190 points.
The first issue is simple to solve, conceptually: simply compare each shooter’s rating to every one of his competitors’ ratings to determine his expected score6. The non-zero-sum problem is thornier, but boils down to score distribution: how should a shooter’s actual score be calculated? The article I followed to develop the initial version of the multiplayer Elo rating engine in Analyst has a few suggestions, but the method I settled on has a few components.
First is match blending. In stage-by-stage mode (Analyst’s default), the algorithm blends in a proportion of your match performance, to even out some stage by stage variation7. If you finished first at a match and third on a stage, and match blend is set to 0.3, your calculated place on that stage is , rewarding you on the stage for the match win.
Second is percentages. For a given rating event8, the Elo algorithm in Analyst calculates a portion of actual score based on your percentage finish. This is easy to justify: coming in 2nd place at 99.5% is essentially a tie, as far as how much it should change your rating, compared to coming in 2nd place at 80%. The percentage component of an actual score is determined by dividing the percent finish on the stage by the sum of all percent finishes on the stage. For instance, in the case of a stage with three shooters finishing 100%, 95%, and 60%, the 95% finisher’s percentage contribution to actual score is .
The winning shooter gets some extra credit based on the gap to second: for his actual score, we treat his percentage as , where P is the percentage of the given shooter. For example, , for an actual score of about 0.404 against 0.392 done the other way around9.
Analyst also calculates a place score according to a method in the article I linked above: the number of shooters minus the actual place finish, scaled to be in the range 0 to 1. Place and percent are both important. The math sometimes expects people who didn’t win to finish above 100%, which isn’t possible in our scoring, but a difficult constraint to encode in Elo’s expected score function. (Remember, the expected score is a simple probability, or at least the descendant of a simple probability.) Granting points for place finish allows shooters who aren’t necessarily contesting stage and match wins to gain Elo even in the cases where percentage finish breaks down. On the other hand, percentage finish serves as a brake on shooters who win most events they enter10. If you always win, eventually you need to start winning by more and more (assuming your competition isn’t getting better too) to keep pushing your rating upward.
Percent and place are blended similar to match/stage blending above, each part scaled by a weight parameter.
That’s the system in a nutshell (admittedly a large nutshell). There are some additional tweaks I’ve added onto it, but first…
The Elo assumptions I break
Although the system I’ve developed is Elo-based, it no longer follows the strict Elo pattern. Among a bevy of minor assumptions about standard Elo that no longer hold, there are two really big ones.
Number one: winning is no longer a guaranteed Elo gain, and losing is no longer a guaranteed Elo loss. If you’re a nationally competitive GM and you only put 5% on the A-class heat at a small local, you’re losing Elo because the comparison between your ratings says you should win by more than that. On the flip side, to manufacture a less likely situation, if you’re 10th of 10 shooters but 92% of someone who usually smokes you, you’ll probably still gain Elo by beating your percentage prediction.
Number two: it’s no longer strictly zero-sum. This arises from a few factors in score calculation, but the end result is that there isn’t a fixed pool of Elo in the system based on the number of competitors. (This is true to a small degree with the system described above, but true to a much larger degree once we get to the next section.)
Other factors I consider
The system I describe above works pretty well. To get it to where it is now, I consider a few other factors. Everything listed below operates by adjusting K, the development coefficient, for given stages (and sometimes even individual shooters), increasing or decreasing the rate of rating change when factors that don’t otherwise affect the rating system suggest it’s too slow or too fast.
Initial placement. For your first 10 stages, you get a much higher K than usual, decreasing down to the normal number. This is particularly useful when new shooters enter mature datasets, allowing them to quickly approach their true rating. Related to initial placement is initial rating: shooters enter the dataset at a rating based on their classification, between 800 for D and 1300 for GM.
Match strength. For matches with a lot of highly-classified shooters (to some degree As, mostly Ms and GMs), K goes up. For matches heavier on the other side of the scale, K goes down.
Match level. Level II matches have a higher K than Level I, and Level III matches have a higher K than Level II.
DQs and DNFs. When a shooter DNFs a stage (a DNF, in Analyst, is defined as zero time and zero hits), that performance is ignored for both changing his own rating, and contributing to rating changes for other shooters. If match blend is on in stage-by-stage mode, it is ignored for DQed shooters. In by-match mode, DQed shooters are ignored altogether.
Pubstomps. If the winning shooter at a match is an M or GM, two or more classes above the second place finisher, and the winner by 25% or more, his K is dramatically reduced, on the theory that wins against significantly weaker competition don’t provide as much rating-relevant information as tighter finishes. This mostly comes into play in lightly-populated divisions.
Zero scores. Elo depends on comparing the relative performances of shooters. One zero score is no different from any other, no matter the skill difference between the shooters, so the algorithm can’t make any assumptions about ratings based on zero scores. If more than 10% of shooters record a zero on a stage, K is reduced.
Network density. Elo works best when operating on densely-connected networks of competitors. The network density modifier (called ‘connectivity’ or ‘connectedness’ most places in the app) increases K when lots of shooters at a given match have recently shot against a lot of other shooters, and decreases K when they haven’t. In a sense, connectivity is another measure of rating reliability: someone with low connectivity might be an artifact of an isolated rating island, shooting against only a few people without exposure to shooters in the broader rating set.
Error. Rating error is a measure of how closely a shooter’s actual scores and expected scores have matched recently. If the algorithm’s predictions have been good, error gets smaller, and K also gets smaller. If the algorithm’s predictions have been bad, error gets bigger, and so does K, to help the rating move toward its correct value more quickly. This is an optional setting, but is currently enabled by default.
Direction. Direction is a measure of how positive or negative a shooter’s recent rating history is: positive direction means that recent events have generally led to increases in rating, with 100 meaning that every recent change is a positive change. Direction awareness increases K when a shooter has highly positive or negative direction and is moving in that direction, and decreases K when a shooter moves opposite a strong direction trend11. Direction awareness is an option, currently disabled by default.
Bomb protection. Bomb protection reduces the impact of single bad stages for highly-rated shooters. Because people with above-average ratings lose much more on the back of a single bad performance than they gain because of a single good performance, ratings can unfairly nosedive in the case of, say, a malfunction or a squib. Bomb protection attempts to detect these isolated occurrences, and reduces K significantly for them. Repeated bad performances lose protection, and allow the rating to begin moving freely again. Bomb protection is an option, currently disabled by default.
In 2024, bomb protection and direction awareness will be enabled for the main ratings I do. Notably, these make the ratings slightly less accurate at predicting match results. It’s sufficiently small an effect that it may not be statistically significant, and it also substantially improves the leaderboards according to the experts who have seen the output. At the same time, the predictions will continue to use the 2023 settings, since (again) they are slightly but consistently more accurate.
In any case, that’s the quick (well, quick-ish) tour of Elo ratings for USPSA. Drop me a comment here, or a DM on Instagram (@jay_of_mars) if you have questions or comments.
The name may change at some point, if USPSA asks, to avoid stepping on their trademark. At the time of writing, I’m not affiliated with USPSA, and they have not publicly sanctioned my work (in either the positive or negative sense of ‘sanction’). ↩
Not ELO— the system is named after its inventor, Hungarian-American physics professor Arpad Elo. It’s pronounced as a word (“ee-low”), not as an initialism (“ee-el-oh”). ↩
You’ll find ‘development coefficient’ in other sources, mostly. I always call it ‘K’. ↩
I will probably refer to these as ‘expected score’ and ‘actual score’ elsewhere in the article. They’re the same thing. ↩
Expected scores and actual scores are scaled so that they sum to 1 across all competitors. This is mainly for convenience and ease of reasoning. ↩
Some, but not all. Stage-by-stage mode works better in my experience: the more comparisons an individual shooter has, the better the output, even if winning stages isn’t quite what we’re measuring in USPSA. ↩
A rating event is a stage, in stage-by-stage mode, or a match in match-by-match mode. ↩
Writing this article, I realize I should probably be making the adjustment for every shooter, but that’ll have to wait until the 2024 preseason12. ↩
I’m a good example of the latter: Analyst isn’t willing to bump my rating by very much at most revolver matches, because it’s expecting me to put large percentages on the field. ↩
The reasoning here is that a shooter whose rating matches his current level of skill should have a direction near 0, which is to say a 50-50 mix of positive and negative changes. ↩
There’s probably a more correct way to generate percentage-based scores in general, but I haven’t set upon it yet, even if I have a few ideas of where I’m not quite on track. ↩
Russia’s logistics situation is baaaad – I remarked to parvusimperator that the only part of the next war you can practice in advance is logistics, and that we Americans have a lot of practice with that, what with flying lobster into the sandbox and all.
We are at least making cool new Burkes – DDG-125 is the first of the Block IIIs, with an enhanced radar that can do air defense and missile defense at the same time. It’s also about the end of the line for the workhorse class: size, weight, power, and cooling are all at their limits.
Who wrote this, China? – “The US shouldn’t be seen to meddle in the affairs of Pacific island nations.” High-minded, but wrong-headed.
Big Tech
Reddit is the most popular search engine; or, Google search is dying – Why? Because Google results are uniformly trash, unless you’re looking for something technical, in which case they’re only mostly trash. “[search term] reddit” is taking over as the way to find out what real people think.
I recently came across a top-[things]-guide article about the PC game Warframe that had clearly been written by an AI, with zero retouching. It fused some lingo specific to the game with a bunch of nonsense that appears in the genre of ‘articles about game mechanics’. That’s the downside to large language models: the more niche your interest, the more likely it is you’ll get pablum out of an LLM.
Deep learning is hitting a wall – A strange thing to post in the wake of DALL-E 2 (the AI that creates pictures based on text descriptions), but I’m pretty much on board with the reasoning.
Inflation – I think this was back when people were still trying to call it transitory.
The power grid is becoming less reliable – Maybe this is the year for solar… On the other hand, Pittsburgh seems to evade regional power outages and gas shortages, because we’re a distribution nexus for both.
I kind of waffle on how much the US should do here. The West does obviously have some responsibility for Ukraine’s independence, given that we gave them assurances to that effect in exchange for their ditching their nukes. On the other hand, getting too tied down in Ukraine makes Taiwan look awfully juicy, and an independent Taiwan is more important than an independent Ukraine in global supply chain terms, at least for now. Mostly what I’m saying is, I’m glad I’m not the president.
Vortex wins the sight portion of the NGSW thing – “It integrates a number of advanced technologies, including a variable magnification optic, backup etched reticle, laser rangefinder, ballistic calculator, atmospheric sensor suite, compass, Intra-Soldier Wireless, visible and infrared aiming lasers, and a digital display overlay.” Cool, I say. Parvusimperator’s take is less optimistic: “It looks heavy, with features no one will use.”
We both agree this one is cool – Microwave weapons for point defense! Masers hitting metal surfaces induce electromagnetic interference in nearby electronics, which is a plot point in my sole published science fiction novella.
How Brazil recovered from rampant inflation – They invented a Unit of Real Value. Prices, wages, and taxes were all listed in URVs, whose value floated relative to the currency of the day, the cruzeiro. That is, a gallon of milk might have been 10 cruzeiros one week, then 20 the next, but either way, it was listed as one URV. Then, once people got used to thinking of prices in term of a stable unit, Brazil declared the URV the real currency1.
Smartphones dangling from trees: delivery drivers gaming the algorithms – It’s a bit tricky to sum up in a headline. An intermediary hangs phones in a tree near delivery hubs, so those devices (by dint of being close to the hub) get priority for accepting jobs. Drivers sync their phones with the intermediary’s phones, so they can grab jobs even if they aren’t nearby.
Squaring the circle: nearer now than it’s ever been – Quanta Magazine reports. The problem has, in the strict sense, been solved for some time, but this is the first solution that doesn’t require some voodoo with zero-area sets of points. The author of the paper thinks he can get it down to 22 pieces or fewer, which would be extremely neat to see animated.
This is, regrettably, not the etymology of the currency now known as the Brazilian real; real means ‘royal’ in Portuguese. It is a clever, and perhaps even intentional, play on words, at least. ↩
India tests air-launched BrahMos missile – “Gee, I wonder what ships those are targeted at,” parvusimperator says. I add, “India’s an awfully big, awfully unsinkable aircraft carrier on China’s SLoC to Africa.”
The taxonomy of narco-subs – H.I. Sutton does not consider the fact that we haven’t caught any of the true submersibles, or the related snorkel ships, evidence of absence. His take is that we know they can build such things, and the fact that we don’t catch any suggests they are building such things.
Looking back on Ukraine’s history with the Blackjack – Post-USSR collapse, they briefly had the largest fleet in the world. Eventually, the airframes were scrapped for money reasons, or sold back to Russia for money reasons.
JWST is part of a hopefully-obsolete model, though – We’re probably a decade or so away from an utter collapse in launch costs. When you can schlep 100 tons into orbit for cheap, why would you bother with one-off special-purpose probes? Or, to quote the article, “For substantially less than current annual SLS development cost, a planetary science-focused Starship launch program could send a fully loaded Starship to every planet at least once per year, except for Mars whose launch windows are less frequent, but which benefits from Starship baseline design and will probably enjoy its own dedicated program.”
In USPSA, I shoot an elegant weapon from a more civilized age: the revolver. The most common question I get, in one form or another, is, “Why?”
Here are some of my answers.
It’s Cool
Coolness is, of course, subjective, so your mileage may vary, but I think revolvers are cool. For one, there’s the cowboy cachet. If you’ve seen my match videos, at least after I started leaning into the spaghetti western theme, I’m sure you can tell I find that compelling.
For another, a revolver is a mechanical marvel: delicate clockwork nevertheless tough enough to survive a cylinder hammering back and forth. Bunches of tiny metal parts, all interlocking perfectly, cooperating to bring the cylinder into line and the hammer down at just the right moment.
And that’s saying nothing of the internal ballistics, which rely on the notion that standard-pressure air is more or less solid to a jet of gas at 20,000 PSI, at least on the timescale needed for a bullet to cross the barrel-cylinder gap and make it out the business end of the gun.
It’s a mechanically and historically fascinating tool. If your ‘why’ was intended to mean ‘why did you get into Revolver over, say, Open or CO?’, that’s why.
It’s Esoteric
Come, reader, I have nothing to hide from you: you know I like weird hipster things. The fact that revolver is an esoteric corner of the USPSA game is a draw to me. Getting to1 work out a lot of how the wheelgun interacts with modern USPSA is an engaging mental exercise for me.
I don’t want to spoil my revolver techniques series too much2, but USPSA Revolver is a layer cake of similarity sponges and difference fillings. There are parts of the game that are the same as in semi-auto divisions, but then you look deeper and there are differences, and then you zoom in to the techniques that underpin those parts of the game and they’re the same, and then you get better at those parts of the game, and they turn different again.
It keeps the gears turning in my head, and the Revolver game has not yet fully revealed itself to me. If you want to know why I keep at it, that’s one reason why.
It Invites—And Rewards—Perfection
USPSA, fundamentally, ends up being more about speed than accuracy. There are only so many points available on a stage, but you can always go faster. Just about anyone can shoot 90% points at a USPSA match. The measure of a shooter is how fast he can do it. There are some wrinkles in that clean formulation. Maybe you shoot 85% points a little faster, or 95% points a little slower. Ultimately, though, your speed improves a whole lot more than your accuracy as you get better at the game.
Inevitably, and not incorrectly, that leads people to shoot as fast as they think they can go to get good hits. Shooters in almost every division except Revolver3 have enough ammunition in the gun to turn the dial a bit more toward speed. Even in Production, if you throw a shot off target and take a fast makeup shot, you’re still in decent shape.
The dial has to go a bit more toward accuracy in Revolver. Shooting a wheelgun, I don’t frequently find myself pulling into a position with extra bullets in the gun. Usually, my stage plan calls for eight shots, and all eight of those shots have to hit, or else there’s going to be a standing reload somewhere. Revolver is a deadeye’s game. If you want to win against solid competition, you have to be able to shoot any given USPSA position with perfect accuracy, and you have to know exactly how fast you can go while doing it.
What do I find compelling about the actual shooting in Revolver division? That.
I’m Good At It
Toward the end of 2021, after a year and a half of shooting almost exclusively revolvers4, I took a few detours into semi-automatic divisions: one day in Carry Optics, one in Open. I shot those guns, and those matches, pretty well. I’m clearly a better shooter now than I was the last time I ran my Carry Optics gun, and that was plain to see in the results.
That said, at the end of the match in Open, I donned the Revolver belt for a run at the classifier. In the aftermath of a 100% run, I remarked to a friend, “I shoot that gun like it’s an extension of my arm.” Revolver clicks for me. For the amount of practice I’ve put in, I run the revolver better compared to some hypothetical baseline skill than I would with the semi-autos. I’m shooting classifiers on a pace that should put me into Grandmaster soon, and in contention to win stages that don’t excessively handicap the wheelgun at the smaller of the two local matches I frequent.
Why revolver? Because I’m good at it, and still getting better.
An uncharitable soul might phrase this ‘having to’, instead. ↩
A series, I might add, that doesn’t take quite as much hedging now that I’ve shot my way into Master class. ↩
Single Stack shooters running major power factor have the same concerns as Revolver here. ↩
There are 25 matches on my record since the start of 2020, of which three, all in 2021, were semi-auto matches. ↩
Well, readers, it’s been more than a month since the last one of these, for which you have my apologies.
October was a busy month for me: three USPSA matches, one of which yielded a trophy, and my birthday toward the end. Now that the summer’s winding down, I should be more able to do these regularly.
Defense
Five B-21s are in final assembly – This story crossed the desk of the Sunday Papers editor on September 21. It has been so long that it’s conceivable they’re done now.
Inside France’s loss of the Aussie submarine contract – The short version seems to be that the French were all, “We will need ze long cigarette breaks and ze padded budgets,” and the Aussies didn’t care for that attitude.
Our best look yet at Rapid Dragon – The Drive points out that, while the system is cool, it’s likely that the US airlift fleet would be busy airlifting things during a peer conflict where ‘more missile trucks’ is a requirement. I suppose it might be that it’s easier to shanghai existing manufacturers into building airlift planes that can double as missile trucks than it would be to get them up to speed on bombers.
Rolls-Royce to re-engine B-52s – Expected service life extended to 2050, which means we’re very likely to see the B-52’s 100th anniversary pass with airframes still in service, in 2055. Mark your calendars!
The J-20A now has domestic engines – CNN calls it an upgrade, of which I am skeptical, but it’s certainly an upgrade in terms of defense industry independence.
Bell completes first Bahraini [s]Cobra[/s] Viper – Why did Bahrain go with the AH-1 instead of the AH-64? Performance might be one reason. The AH-1 is a substantially more maneuverable platform—it’s a ton or two lighter, and only down 180 shaft horsepower over the Apache.
Harrier pilots use a meatball too – I should get back into DCS some, once my gaming computer is running again. (My 10-year-old RAM sure picked a bad time to crap out on me.)
A nifty AUKUS map – Mainly because of the projection. It’s centered on Guam, so that all lines of azimuth from Guam are accurate. You get a good sense for the shape of the lines of communication between the AUKUS members, as well as the strategic shape of Pacific lines of communication.
Science and Technology
Starship is still not understood – There’s going to be a massive economic revolution in space in the next decade or so, and NASA is still planning missions like it’s 1994. When you can chuck 100 tons into space for $10 million, suddenly optimizing ruthlessly for mass and building billion-dollar rovers doesn’t seem like such a good use of time.
E3D, manufacturer of 3D printer accessories, plans to patent its future innovations – Because they can’t survive as a company when they have to compete with near-instant Chinese ripoffs of their products, and then also deal with supporting said ripoffs. The 3D printing community is howling, but honestly, I don’t hate their approach here. They say they won’t enforce their patents against hobbyists and academics, which is to my mind the most egregious part of the patent system.
Speaking of, there’s a geomagnetic storm coming today – If you’re at 50 degrees geomagnetic latitude or points north, you may be able to see auroras tonight. Unless you’re here with us in Pittsburgh, in which case you won’t, because it’s cloudy.
Starlink satellites stand in for GPS – Satellites with published ephemeris data constantly transmitting accurate timestamps can be used for location? News at 11.
Is Evergrande finally going to collapse? – Story from 9/21. As of this writing, no, but it could still happen. I feel like Evergrande collapse stories are kind of like Three Gorges Dam collapse stories, in that they’re tired and predictable up until when they actually happen.
Closing in on COVID’s origins – If it circulated in animals and jumped to humans, you’d expect to find it in animals. Except… “Chinese scientists searched for a host in early 2020, testing more than 80,000 animals from 209 species, including wild, domesticated and market animals. As the WHO investigation reported, not a single animal infected with SARS-CoV-2 was found.”
Shipping pallets are the low-stakes version of container shortages – Well, partially shortages, and partially how there are competing pallet systems. There are the ‘whitewood’ ones you think of when you think of a shipping pallet, and then there are blue-painted ones that are rented by a central company rather than sold as part of the shipment.
I won Revolver division at the Virginia State USPSA championship, and got a nifty belt for my trouble.
Grab Bag
Why you’re Christian – Philosophically, as a citizen of a Western nation, even if you don’t hold to the religion itself.
Smith and Wesson ditches Massachusetts – For its headquarters, at least. Some manufacturing will remain in MA. Not a lot of firearms companies left in the historically innovative Northeast. Ruger’s in New Hampshire, which barely even counts as the Northeast, given its commitment to freedom.

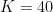
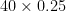
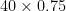 makes 30, for when player 1 wins.
makes 30, for when player 1 wins.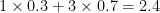

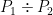
 , for an actual score of about 0.404 against 0.392 done the other way around
, for an actual score of about 0.404 against 0.392 done the other way around