It’s commonly thought that the Bismarck was the mightiest warship in May of 1941, when she sortied with Prinz Eugen, sunk the Hood, was crippled by Swordfish torpedo planes, and then sunk by a vengeful Royal Navy flotilla.
However, this is wrong. Wrong wrong WRONG!
Okay then.
“Magic mirror, on the wall, who’s the mightiest ship of all?”
Well now. The magic mirror would tell us the tale of the legendary Billy Mitchell, and that airpower is superior. Proven when he took out the Ostfriesland with bombs. The aircraft has more range and more effective antiship striking power. It is the carrier that is champion of types.
But which carrier? Well, she must be active, and therefore must be commissioned. And clearly the two navies that had carriers worth noting in the Second World War were the US Navy and the Imperial Japanese Navy, so let’s look at those.
For the Imperial Japanese Navy, the mightiest flattop gal from the Far East is IJN Zuikaku1. Technically, the Kaga carries more planes, but both carry the same number of planes in ready, immediately flyable condition. No points for more stowed aircraft, which are disassembled. Plus Zuikaku has better anti-aircraft armament and thus better defense. She’s also faster, and speed helps generate wind over the flight deck, making takeoffs easier. Sorry Kaga.
For the US Navy, the mightiest flattop gal from the West is USS Enterprise2. The Big E. The Grey Ghost. One of three American carriers to be active at the start and survive the war. She had the biggest air wing in the USN in May of ’41.
Let’s get it on!
First, design compliment. Zuikaku was designed to carry 72 flyable aircraft, plus 12 disassembled spares. Enterprise was designed around a compliment of 90 flyable aircraft. The US Navy liked big air wings on its carriers, and to that end designed operations on using half the flight deck as a deck park, even during flight operations. So that’s points to the Enterprise.
A brief interlude. Many of you are no doubt wondering why I don’t compare the air wings themselves. The USN had the excellent SBD Dauntless dive bomber, the good F4F Wildcat fighter, and the outmoded TBD Devastator torpedo bomber. The IJN had the superlative A6M Zero fighter, the solid B5N Kate torpedo bomber, and the obsolescent D3A Val Dive bomber. I might also talk about the relative experience levels of the flight crews. But I won’t. Neither aircraft purchasing decisions, nor delays in production, nor failures to secure timely replacements, nor even how much time had been spent beating up on minor league air forces are the purview of ship designers. It isn’t reasonable to award or deduct points for things beyond their control. Besides, adding planes into the mix then brings up a question of doctrine, and the Japanese favored using float planes from cruisers as scouts. But the US Navy used SBD Dauntless dive bombers as scouts, which were embarked on the carrier. This will get very complicated very quickly if you’re trying to pick a winner from a hypothetical battle, as you might expect to be able to do if you were adding an aircraft comparison into the mix. Do we spot the Japanese some cruisers so they can scout too? Do we magically assume they can see the US Navy? Are we instead trying to make a hypothetical battle modeling of task forces, since these ships never travel alone? I should also point out that down that road lies the madness of trying to figure out how many fighters are on CAP duty/alert, and how many are in a strike force, and then comparing dissimilar types with unequal numbers. Lunacy. So I shan’t waste any more time discussing the matter.
Defensively, the best defense is the carrier’s own air wing. But that is not always enough. What about the guns? No points for antiship capability, of course. It is somewhat difficult to evaluate antiaircraft guns comparatively, so we’ll take as couple of proxy measures total throw weight per minute of all embarked guns in May of ’41, and AA Ceiling for the heavy AA. In my calculations, I will take the best rating I can find for sustained rate of fire, as a simplifying metric for comparison.
Enterprise had, in 1941, eight 5″/38 guns in single mounts, plus sixteen 1.1″/75 autocannons in quad mounts, and twenty four .50″ M2 machine guns. The 5″/38 is the best DP AA naval gun of the war. In the Enterprise’s pedestal mounts, these are good for about fifteen rounds per minute, with each shell weighing 55.18 lbs. So the 5″/38s give 6,621.6 lbs per minute. The Quad 1.1″ guns were less well liked, and were generally replaced with the more powerful Bofors 40mm as the war progressed. But that is in the future. Each shell of the 1.1″/75 weighed 0.917 lbs and the guns had a rate of fire of 100 rounds per minute. This gives us 1,467.21284 lbs per minute. The famous M2 Browning fired a round weighing 0.107 lbs at a rate of 550 rounds per minute. We have 24, so that’s another 1,284 lbs per minute. So in one minute, Enterprise’s AA guns can put out 9,372.8 lbs of aircraft killing pain. Maximum ceiling on the 5″/38s is 37,200 ft.
Zuikaku had, in 1941, sixteen 5″/40 guns in eight twin mounts, plus 36 25mm/60 autocannons in a dozen triple mounts. The 5″/40 gun was the standard DP heavy AA gun for the Imperial Japanese Navy. It fired 51.7 lb projectiles at a rate of eight rounds per minute, giving a total of 7,052.8 lbs. The Japanese 25 mm autocannon was a clone of a Hotchkiss design. Later in the war, the Imperial Japanese Navy would regret not developing something punchier, given how heavily built American naval aircraft were. The thirty six guns each had a rate of fire of 120 rounds per minute, and fired a 0.55 lb. shell, yielding another 2,376 lbs. So Zuikaku can put out 9,428.8 lbs of defensive firepower. Maximum ceiling on the 5″/40s is 30,840 ft.
So Zuikaku has a more powerful antiaircraft suite at this point in the war. On a raw points tally basis, that’s one point each, but we want to weight air wing heavier. That’s more useful for an aircraft carrier. The Enterprise was fitted with radar before the war. Zuikaku never got any.
So, overall, the Enterprise is the more powerful carrier. So she gets the crown of Most Powerful Warship in May of ’41.
Those of you who aren’t grumbling about me ignoring aircraft design are no doubt thinking “Fine, parvusimperator. But what about the old battlewagons? Surely Bismarck is the most powerful battleship in May of ’41. Yamato hasn’t been commissioned yet!
Wrong again.
“Magic mirror, on the wall, who’s the mightiest battleship of all?”
Battleships are a lot easier to compare than aircraft carriers. Pesky debates about aircraft don’t enter into it. Battleships fight with guns. Bismarck had eight 15″ guns, each firing an armor piercing shell that weighed 1,764 lbs. Well and good.
As mentioned before, Yamato isn’t commissioned yet. So her monster 18″ guns don’t enter the picture. And, my personal favorites, the Iowas aren’t done yet either. Nor are the South Dakotas or Britain’s Vanguard. What we have are treaty built battleships, and pre-1922 things.
Let’s start with which ships have 16″ guns? That would be the Nelsons, the Colorados, the Nagatos, and the North Carolinas. The Colorados have eight guns, and all the rest have nine. Of these, the North Carolinas are the only ones built after the end of the 1922 Washington Treaty-imposed ‘building holiday’. We might expect them to be better, being newer.
And for once, we’re totally right. The North Carolinas are not only the prettiest of the 16″ gunned battleships in commission in May of 1941, but they’re also the most powerful by far. The US Navy’s Ordnance Bureau had done a bunch of testing between the wars, and reckoned that heavy shells were best. As a result, when they went to design a new 16″ gun, they not only made the gun lighter and simpler, but also made the shells really heavy. The resulting Mark 8 “Superheavy” AP rounds weighed 2,700 lbs. North Carolina’s broadside is an impressive 24,300 lbs. Bismarck can only manage 14,112 lbs.
Discussion of armor protection is more complicated, and I’ll leave that for another article. But suffice it to say North Carolina does that better too.
There you have it. The mightiest battle wagon in May of ’41 is the USS North Carolina.
1.) Shokaku would also work here, and she’s the class leader and namesake. So perhaps the honor should be hers. But Zuikaku was luckier. And survived longer. Shokaku was damaged a bunch first, and sank first. So Zuikaku gets the nod here. Luck is important for a ship.
2.) Or Yorktown, who is the class leader (again, and namesake). But Enterprise is a legend, and the most decorated American ship of WWII. How could I not pick her?

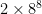 : it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case,
: it comes to about 33 million entries, or 60-some megabytes using an integer table entry. OpenTafl, which has to support everything from lowly brandub to the massive alea evangelii, needs, in the maximum case, 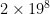 , or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.
, or 34 billion table entries, which takes almost 70 gigabytes of memory. Most people aren’t going to have that to spare.